

These are my notable academic publications.
- A more comprehensive list of my publications can be found in Google Scholar
- I regularly upload all PDF versions of my publications to Research Gate
- I upload my presentations in SlideShare or SpeakerDeck.
- Selected publications are indicated with ★
- Nominated or best paper awards are indicated with
- Papers awarded with artifact badges are indicated with the associated award icons.
2026
Abir Hossen, Mohammad Ali Javidian, Vignesh Narayanan, Jason M. O'Kane, Pooyan Jamshidi
Arxiv (ICML)
Abstract
Multi-fidelity Bayesian optimization (MFBO) accelerates the search for the global optimum of black-box functions by integrating inexpensive, low-fidelity approximations. The central task of an MFBO policy is to balance the cost-efficiency of low-fidelity proxies against their reduced accuracy to ensure effective progression toward the high-fidelity optimum. Existing MFBO methods primarily capture associational dependencies between inputs, fidelities, and objectives, rather than causal mechanisms, and can perform poorly when lower-fidelity proxies are poorly aligned with the target fidelity. We propose RESCUE (REducing Sampling cost with Causal Understanding and Estimation), a multi-objective MFBO method that incorporates causal calculus to systematically address this challenge. RESCUE learns a structural causal model capturing causal relationships between inputs, fidelities, and objectives, and uses it to construct a probabilistic multi-fidelity (MF) surrogate that encodes intervention effects. Exploiting the causal structure, we introduce a causal hypervolume knowledge-gradient acquisition strategy to select input-fidelity pairs that balance expected multi-objective improvement and cost. We show that RESCUE improves sample efficiency over state-of-the-art MF optimization methods on synthetic and real-world problems in robotics, machine learning (AutoML), and healthcare.2025
Omid Gheibi, Christian Kaetner, Pooyan Jamshidi
Arxiv (TOSEM)
Abstract
Performance-influence models are beneficial for understanding how configurations affect system performance, but their creation is challenging due to the exponential growth of configuration spaces. While gray-box approaches leverage selective structural knowledge (like the module execution graph of the system) to improve modeling, the relationship between this knowledge, a system's characteristics (we call them structural aspects), and potential model improvements is not well understood. This paper addresses this gap by formally investigating how variations in structural aspects (e.g., the number of modules and options per module) and the level of structural knowledge impact the creation of opportunities for improved modular performance modeling. We introduce and quantify the concept of modeling hardness, defined as the inherent difficulty of performance modeling. Through controlled experiments with synthetic system models, we establish an analytical matrix to measure these concepts. Our findings show that modeling hardness is primarily driven by the number of modules and configuration options per module. More importantly, we demonstrate that both higher levels of structural knowledge and increased modeling hardness significantly enhance the opportunity for improvement. The impact of these factors varies by performance metric; for ranking accuracy (e.g., in debugging task), structural knowledge is more dominant, while for prediction accuracy (e.g., in resource management task), hardness plays a stronger role. These results provide actionable insights for system designers, guiding them to strategically allocate time and select appropriate modeling approaches based on a system's characteristics and a given task's objectives.
Haesue Baik, Chenyang Yang, Vasudev Vikram, Pooyan Jamshidi, Rohan Padhye, Christian Kaestner
International Workshop on Search-Based and Fuzz Testing (SBFT)
Abstract
Highly-configurable software often includes performance-sensitive configuration options. There are performance expectations in different configurations, but these expectations may not hold due to inaccurate mental models, corner cases, or unanticipated interactions with other options. We propose differential performance fuzzing of configuration options, a fuzzing technique that uses differential performance feedback to automatically identify inputs that violate these expectations for specific configuration changes. By guiding fuzzing toward scenarios where a supposedly faster configuration performs worse, differential performance fuzzing reveals unexpected performance behavior effectively. In our preliminary evaluation, our method identified unexpected performance gains in configurations presumed slower for 4 configuration options in Closure, demonstrating the potential for detecting performance issues in real-world applications.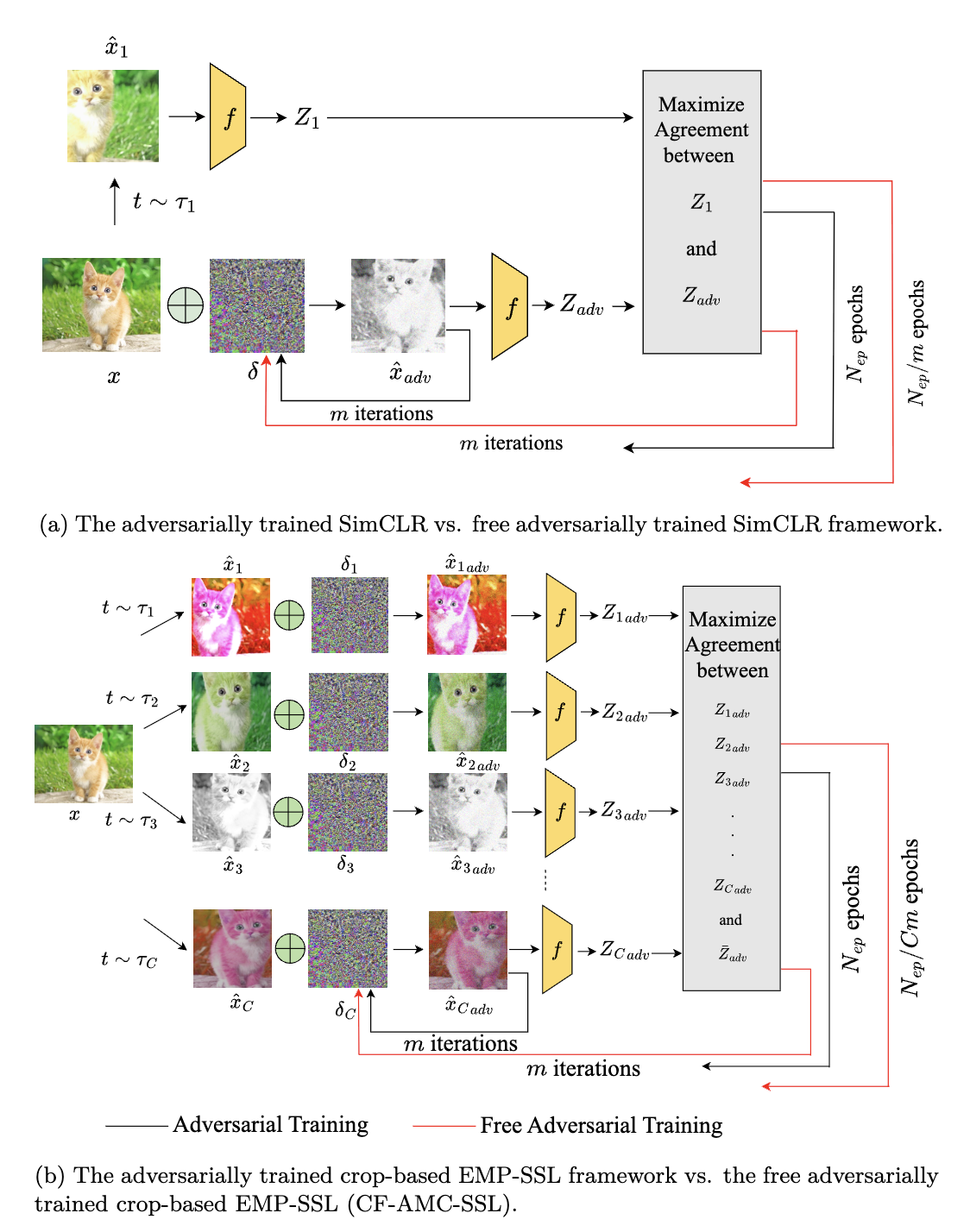
Fatemeh Ghofrani, Mehdi Yaghouti, Pooyan Jamshidi
Transactions on Machine Learning Research (TMLR)
Abstract
Self-supervised learning (SSL) has made significant strides in learning image representations, yet its principles remain partially understood, particularly in adversarial scenarios. This work explores the interplay between SSL and adversarial training (AT), focusing on whether this integration can yield robust representations that balance computational efficiency, clean accuracy, and robustness. A major challenge lies in the inherently high cost of AT, which combines an inner maximization problem (generating adversarial examples) with an outer minimization problem (training representations). This challenge is exacerbated by the extensive training epochs required for SSL convergence, which become even more demanding in adversarial settings. Recent advances in SSL, such as Extreme-Multi-Patch Self-Supervised Learning (EMP-SSL), have demonstrated that increasing the number of patches per image instance can significantly reduce the number of training epochs. Building on this, we introduce Robust-EMP-SSL, an extension of EMP-SSL specifically designed for adversarial training scenarios. Robust-EMP-SSL is a framework that leverages multiple crops per image to enhance data diversity, integrates invariance terms with regularization to prevent collapse, and optimizes adversarial training efficiency by reducing the required training epochs. By aligning these components, Robust-EMP-SSL enables the learning of robust representations while addressing the high computational costs and accuracy trade-offs inherent in adversarial training. This study poses a central question: How can multiple crops or diverse patches, combined with adversarial training strategies, achieve trade-offs between computational efficiency, clean accuracy, and robustness? Our empirical results show that Robust-EMP-SSL not only accelerates convergence, but also achieves a superior balance between clean accuracy and adversarial robustness, outperforming SimCLR, a widely used self-supervised baseline that, like other methods, relies on only two augmentations. Furthermore, we propose the Cost-Free Adversarial Multi-Crop Self-Supervised Learning (CF-AMC-SSL) method, which incorporates free adversarial training into the multi-crop SSL framework. CF-AMC-SSL demonstrates the potential to enhance both clean accuracy and adversarial robustness under reduced epoch conditions, further improving efficiency. These findings highlight the potential of Robust-EMP-SSL and CF-AMC-SSL to make SSL more practical in adversarial scenarios, paving the way for future empirical explorations and real-world applications.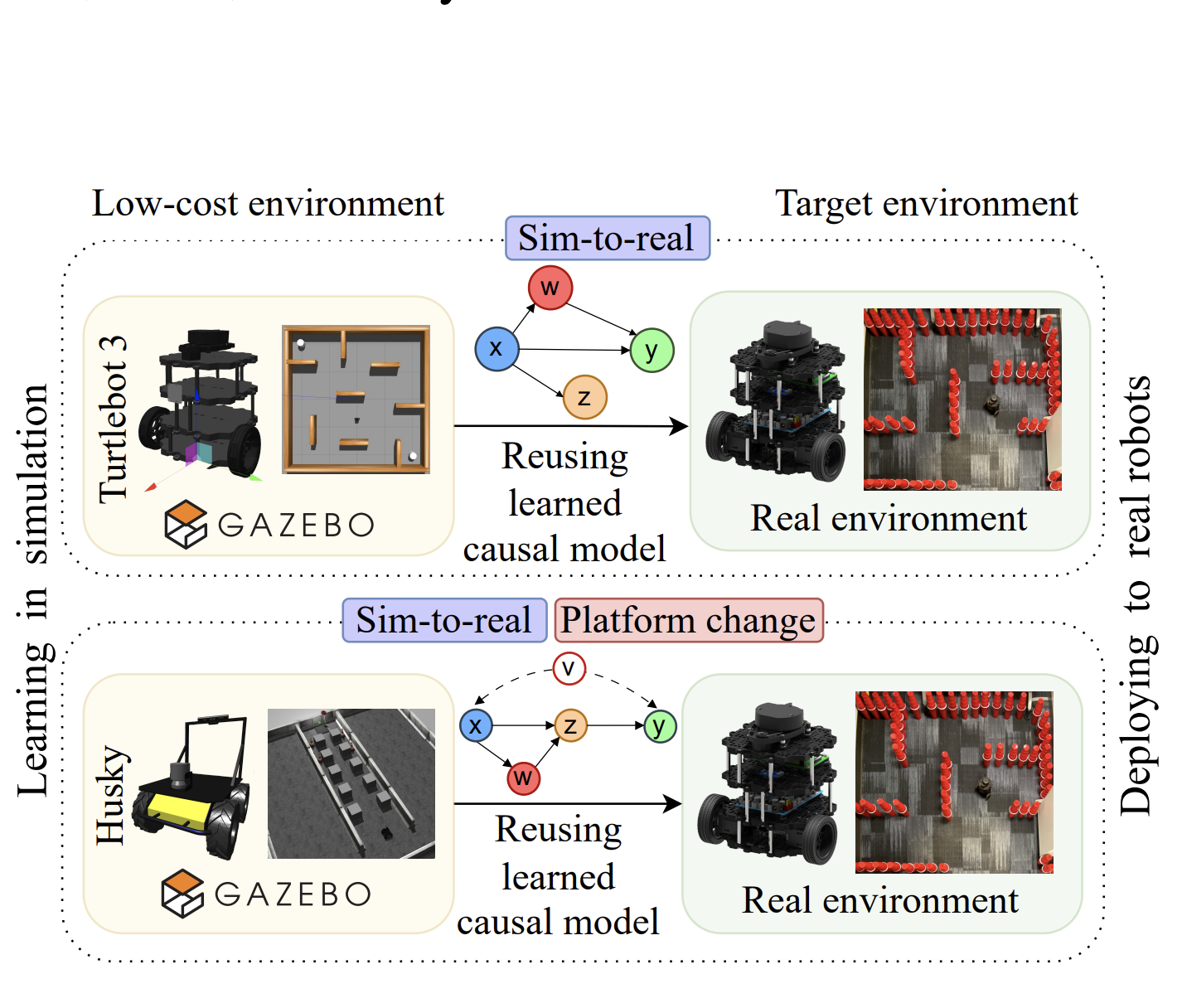
Md Abir Hossen, Sonam Kharade, Jason M. O'Kane, Bradley Schmerl, David Garlan, Pooyan Jamshidi
IEEE Transactions on Robotics (T-RO)
Abstract
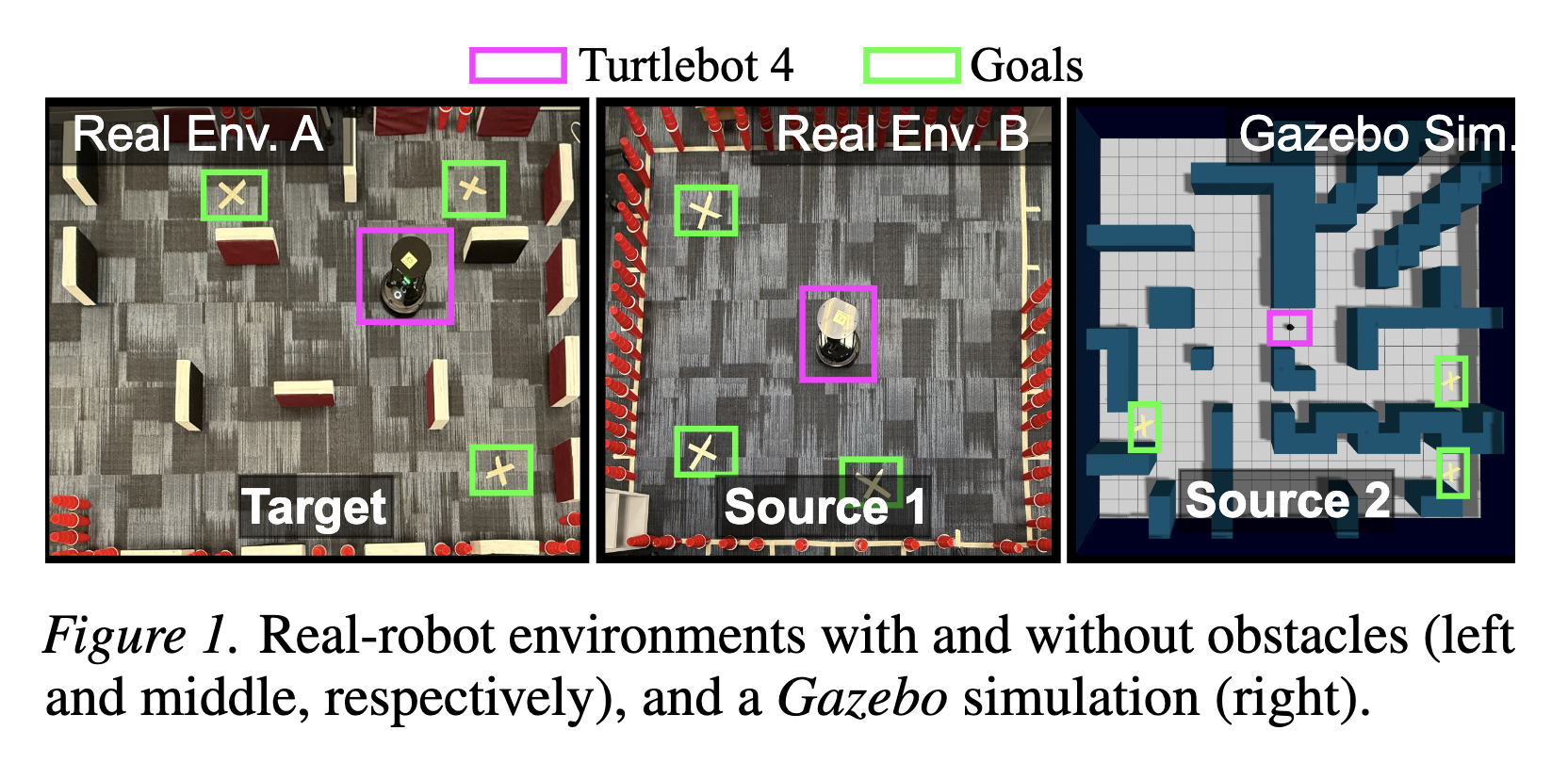
Robotic systems are typically composed of various subsystems, such as localization and navigation, each encompassing numerous configurable components (e.g., selecting different planning algorithms). Once an algorithm has been selected for a component, its associated configuration options must be set to the appropriate values. Configuration options across the system stack interact non-trivially. Finding optimal configurations for highly configurable robots to achieve desired performance poses a significant challenge due to the interactions between configuration options across software and hardware that result in an exponentially large and complex configuration space. These challenges are further compounded by the need for transferability between different environments and robotic platforms. Data efficient optimization algorithms (e.g., Bayesian optimization) have been increasingly employed to automate the tuning of configurable parameters in cyber-physical systems. However, such optimization algorithms converge at later stages, often after exhausting the allocated budget (e.g., optimization steps, allotted time) and lacking transferability. This paper proposes CURE -- a method that identifies causally relevant configuration options, enabling the optimization process to operate in a reduced search space, thereby enabling faster optimization of robot performance. CURE abstracts the causal relationships between various configuration options and robot performance objectives by learning a causal model in the source (a low-cost environment such as the Gazebo simulator) and applying the learned knowledge to perform optimization in the target (e.g., Turtlebot 3 physical robot). We demonstrate the effectiveness and transferability of CURE by conducting experiments that involve varying degrees of deployment changes in both physical robots and simulation.2024
Hossein KhademSohi, Mohammadamin Abedi, Yani Ioannou, Steve Drew, Pooyan Jamshidi, and Hadi Hemmati
Transactions on Machine Learning Research (TMLR)
Abstract
Deep Neural Networks (DNNs) have become an essential component in many application domains, including web-based services. A variety of these services require high throughput and (close to) real-time features, for instance, to respond or react to users’ requests or to process a stream of incoming data on time. However, the trend in DNN design is towards larger models with many layers and parameters to achieve more accurate results. Although these models are often pre-trained, the computational complexity in such large models can still be relatively significant, hindering low inference latency. In this paper, we propose an end-to-end automated early exiting solution to improve the performance of DNN-based vision services in terms of computational complexity and inference latency. Our method adopts the ideas of self-distillation of DNN models and early exits specifically for vision applications. The proposed solution is an automated unsupervised early exiting mechanism that allows early exiting of a large model during inference time if the early exit model in one of the early exits is confident enough for final prediction. One of the main contributions of this paper is that we have implemented the idea as an unsupervised early exiting, meaning that the early exit models do not need access to training data and perform solely based on the incoming data at run-time, making it suitable for applications using pre-trained models. The results of our experiments on two vision tasks (image classification and object detection) show that, on average, early exiting can reduce the computational complexity of these services up to 58% (in terms of FLOP count) and improve their inference latency up to 46% with a low to zero reduction in accuracy. Our approach also outperforms existing methods, particularly on complex models and larger datasets. It achieves a notable reduction in latency of 51.6% and 30.4% on CIFAR100-Resnet50, with an accompanying increase in accuracy of 2.31% and 0.72%, on average, compared to GATI and BranchyNet.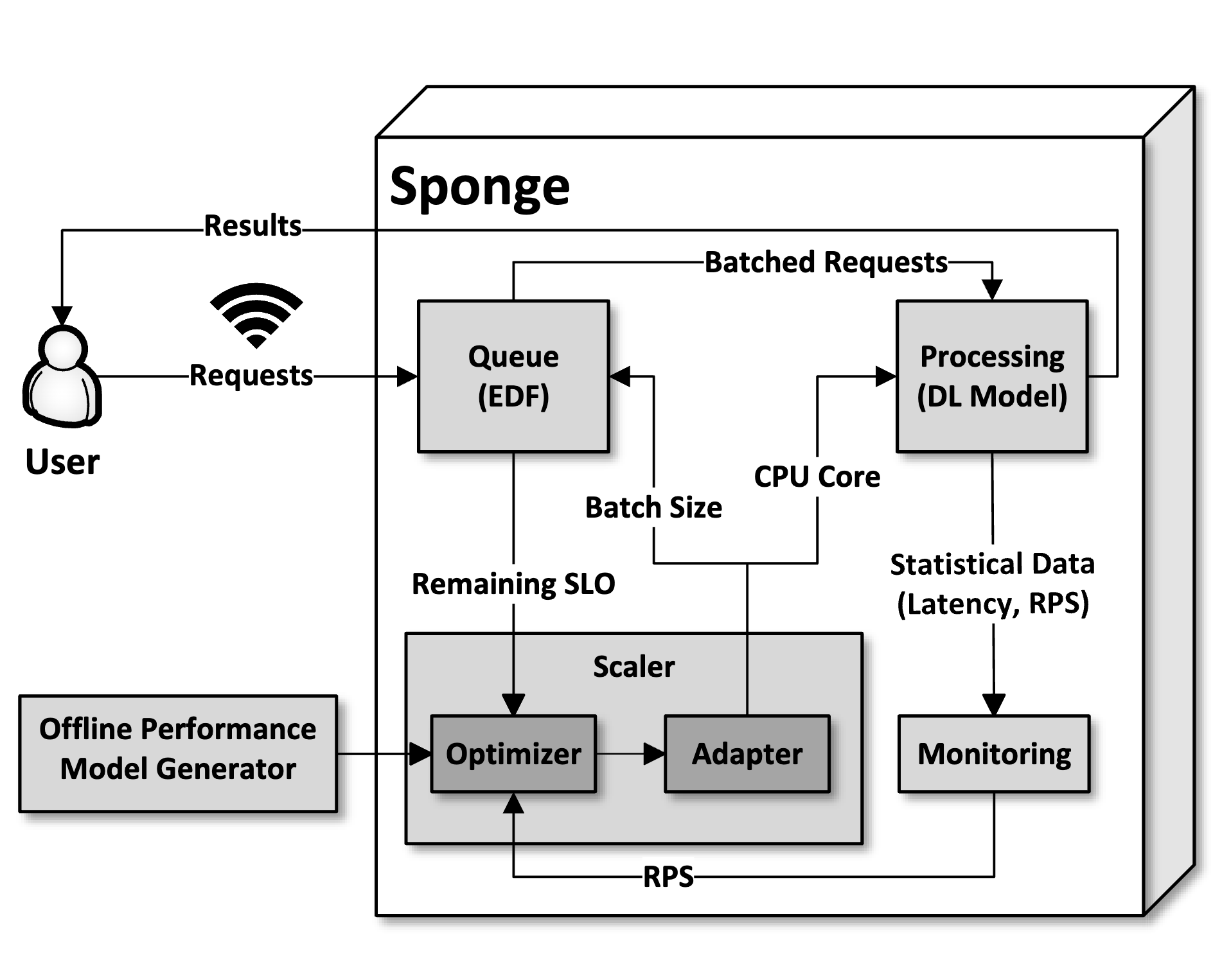
Kamran Razavi, Saeid Ghafouri, Max Mühlhäuser, Pooyan Jamshidi, Lin Wang
ACM EuroMLSys@EuroSys (EuroMLSys)
Abstract
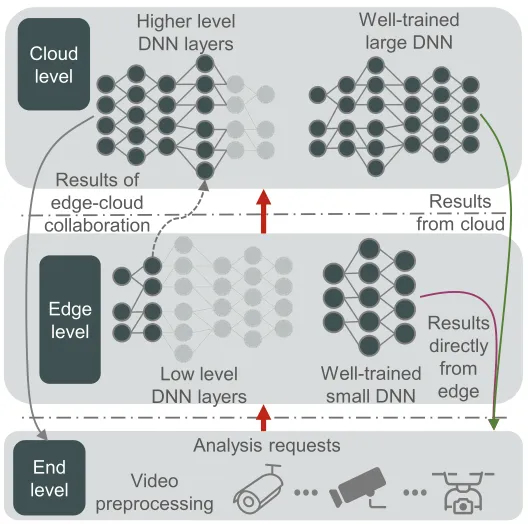
Mobile and IoT applications increasingly adopt deep learning inference to provide intelligence. Inference requests are typically sent to a cloud infrastructure over a wireless network that is highly variable, leading to the challenge of dynamic Service Level Objectives (SLOs) at the request level. This paper presents Sponge, a novel deep learning inference serving system that maximizes resource efficiency while guaranteeing dynamic SLOs. Sponge achieves its goal by applying in-place vertical scaling, dynamic batching, and request reordering. Specifically, we introduce an Integer Programming formulation to capture the resource allocation problem, providing a mathematical model of the relationship between latency, batch size, and resources. We demonstrate the potential of Sponge through a prototype implementation and preliminary experiments and discuss future works.
Claire Le Goues, Sebastian Elbaum, David Anthony, Celik Berkay, Mauricio Castillo-Effen, Nikolaus Correll, Pooyan Jamshidi, Morgan Quigley, Trenton Tabor, and Qi Zhu
Arxiv (Arxiv)
Abstract
Robots are experiencing a revolution as they permeate many aspects of our daily lives, from performing house maintenance to infrastructure inspection, from efficiently warehousing goods to autonomous vehicles, and more. This technical progress and its impact are astounding. This revolution, however, is outstripping the capabilities of existing software development processes, techniques, and tools, which largely have remained unchanged for decades. These capabilities are ill-suited to handling the challenges unique to robotics software such as dealing with a wide diversity of domains, heterogeneous hardware, programmed and learned components, complex physical environments captured and modeled with uncertainty, emergent behaviors that include human interactions, and scalability demands that span across multiple dimensions. Looking ahead to the need to develop software for robots that are ever more ubiquitous, autonomous, and reliant on complex adaptive components, hardware, and data, motivated an NSF-sponsored community workshop on the subject of Software Engineering for Robotics, held in Detroit, Michigan in October 2023. The goal of the workshop was to bring together thought leaders across robotics and software engineering to coalesce a community, and identify key problems in the area of SE for robotics that that community should aim to solve over the next 5 years. This report serves to summarize the motivation, activities, and findings of that workshop, in particular by articulating the challenges unique to robot software, and identifying a vision for fruitful near-term research directions to tackle them.
Saeid Ghafouri, Kamran Razavi, Mehran Salmani, Alireza Sanaee, Tania Lorido-Botran, Lin Wang, Joseph Doyle, Pooyan Jamshidi
Journal of Systems Research (JSys)
Abstract
Efficiently optimizing multi-model inference pipelines for fast, accurate, and cost-effective inference is a crucial challenge in ML production systems, given their tight end-to-end latency requirements. To simplify the exploration of the vast and intricate trade-off space of accuracy and cost in inference pipelines, providers frequently opt to consider one of them. However, the challenge lies in reconciling accuracy and cost trade-offs. To address this challenge and propose a solution to efficiently manage model variants in inference pipelines, we present IPA, an online deep-learning Inference Pipeline Adaptation system that efficiently leverages model variants for each deep learning task. Model variants are different versions of pre-trained models for the same deep learning task with variations in resource requirements, latency, and accuracy. IPA dynamically configures batch size, replication, and model variants to optimize accuracy, minimize costs, and meet user-defined latency SLAs using Integer Programming. It supports multi-objective settings for achieving different trade-offs between accuracy and cost objectives while remaining adaptable to varying workloads and dynamic traffic patterns. Extensive experiments on a Kubernetes implementation with five real-world inference pipelines demonstrate that IPA improves normalized accuracy by up to 35% with a minimal cost increase of less than 5%.2023
Fatemeh Ghofrani, Mehdi Yaghouti, Pooyan Jamshidi
New Frontiers in Adversarial Machine Learning at ICML'23 (AdvML-Frontiers'23)
Abstract
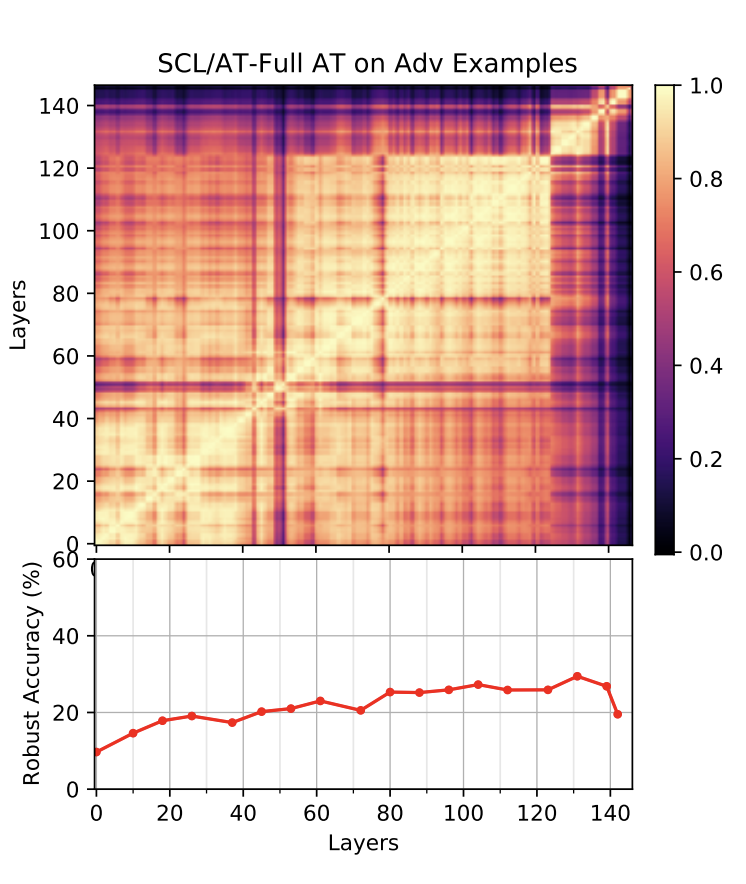
To advance the understanding of robust deep learning, we delve into the effects of adversarial training on self-supervised and supervised contrastive learning alongside supervised learning. Our analysis uncovers significant disparities between adversarial and clean representations in standard-trained networks across various learning algorithms. Remarkably, adversarial training mitigates these disparities and fosters the convergence of representations toward a universal set, regardless of the learning scheme used. Additionally, increasing the similarity between adversarial and clean representations, particularly near the end of the network, enhances network robustness. These findings offer valuable insights for designing and training effective and robust deep learning networks.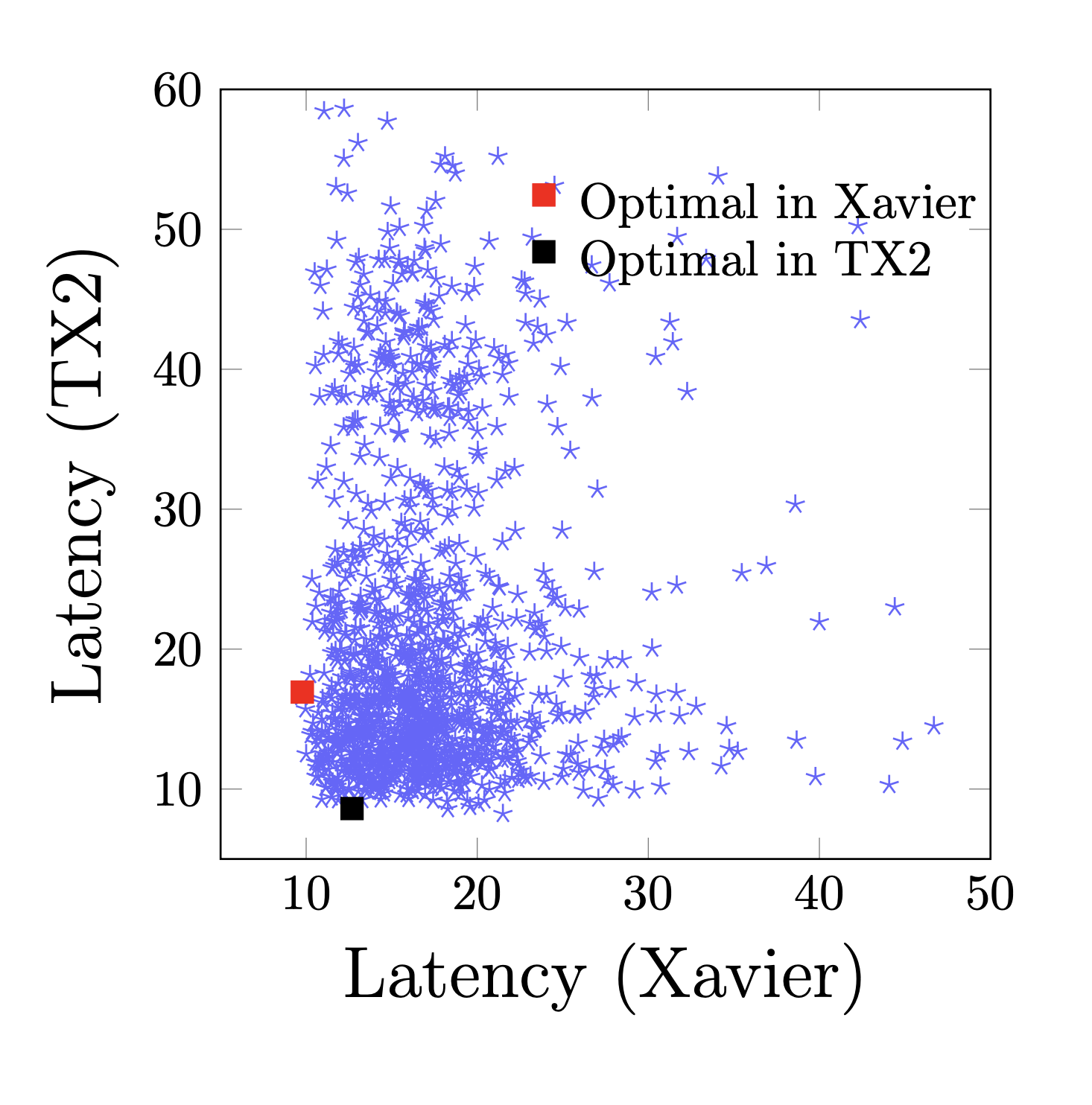
Shahriar Iqbal, Ziyuan Zhong, Iftakhar Ahmad, Baishakhi Ray, Pooyan Jamshidi
ACM Symposium on Cloud Computing (SoCC)
Abstract
Modern computer systems are highly-configurable, with hundreds of configuration options interacting, resulting in enormous configuration space. As a result, optimizing performance goals (e.g., latency) in such systems is challenging. Worse, owing to evolving application requirements and user specifications, these systems face frequent uncertainties in their environments (e.g., hardware and workload change), making performance optimization even more challenging. Recently, transfer learning has been applied to address this problem by reusing knowledge from the offline configuration measurements of an old environment, aka, source to a new environment, aka, target. These approaches typically rely on predictive machine learning (ML) models to guide the search for finding interventions to optimize performance. However, previous empirical research showed that statistical models might perform poorly when the deployment environment changes because the independent and identically distributed (i.i.d.) assumption no longer holds. To address this issue, we propose Cameo -- a method that sidesteps these limitations by identifying invariant causal predictors under environmental changes, enabling the optimization process to operate on a reduced search space, leading to faster system performance optimization. We demonstrate significant performance improvements over the state-of-the-art optimization methods on five highly configurable computer systems, including three MLperf deep learning benchmark systems, a video analytics pipeline, and a database system, and studied the effectiveness in design explorations with different varieties and severity of environmental changes and show the scalability of our approach to colossal configuration spaces.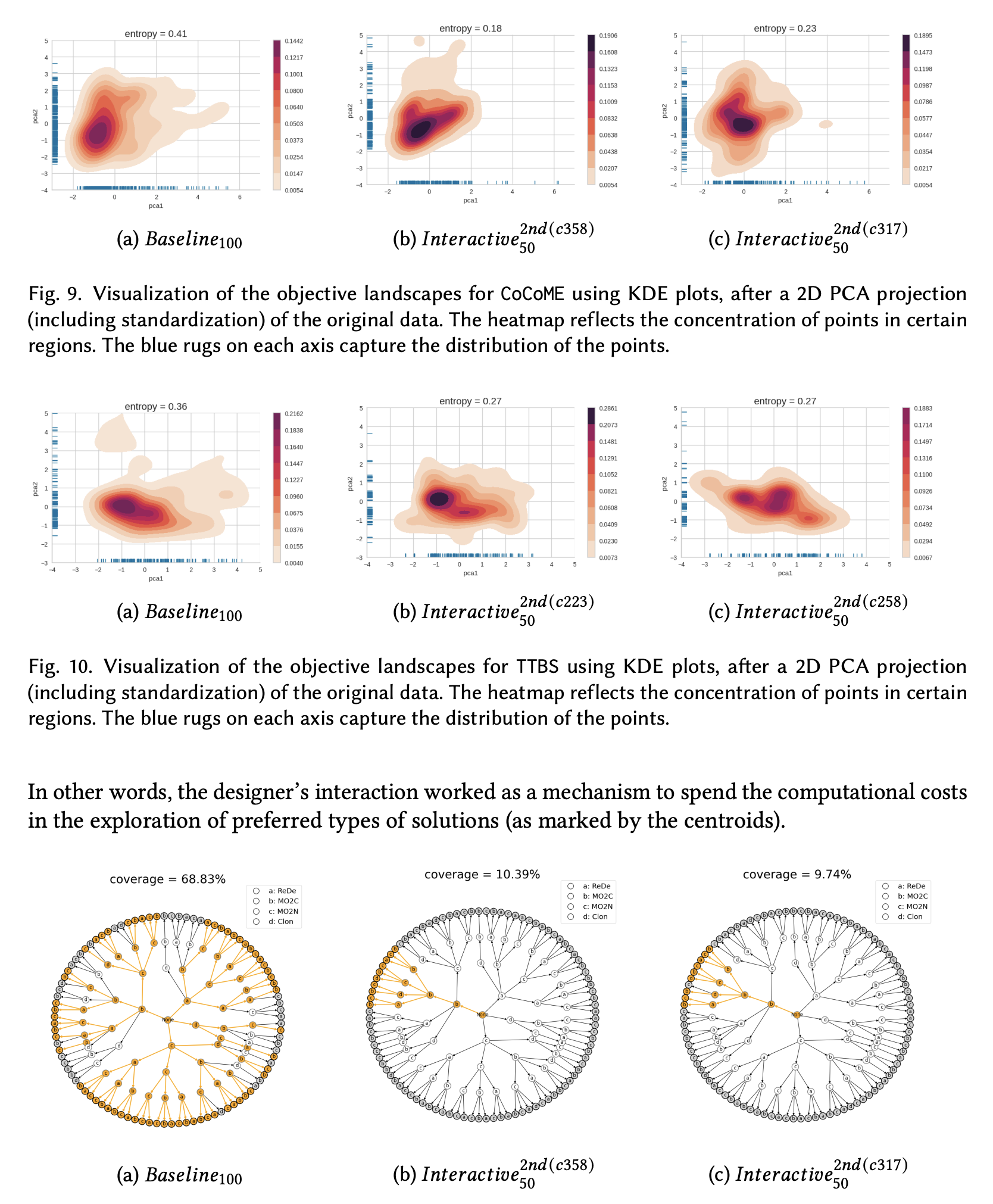
Vittorio Cortellessa, J. Andres Diaz-Pace, Daniele Di Pompeo, Sebastian Frank, Pooyan Jamshidi, Michele Tucci, André van Hoorn
ACM Transactions on Software Engineering and Methodology (TOSEM)
Abstract
Software architecture optimization aims to enhance non-functional attributes like performance and reliability while meeting functional requirements. Multi-objective optimization employs metaheuristic search techniques, such as genetic algorithms, to explore feasible architectural changes and propose alternatives to designers. However, the resource-intensive process may not always align with practical constraints. This study investigates the impact of designer interactions on multi-objective software architecture optimization. Designers can intervene at intermediate points in the fully automated optimization process, making choices that guide exploration towards more desirable solutions. We compare this interactive approach with the fully automated optimization process, which serves as the baseline. The findings demonstrate that designer interactions lead to a more focused solution space, resulting in improved architectural quality. By directing the search towards regions of interest, the interaction uncovers architectures that remain unexplored in the fully automated process.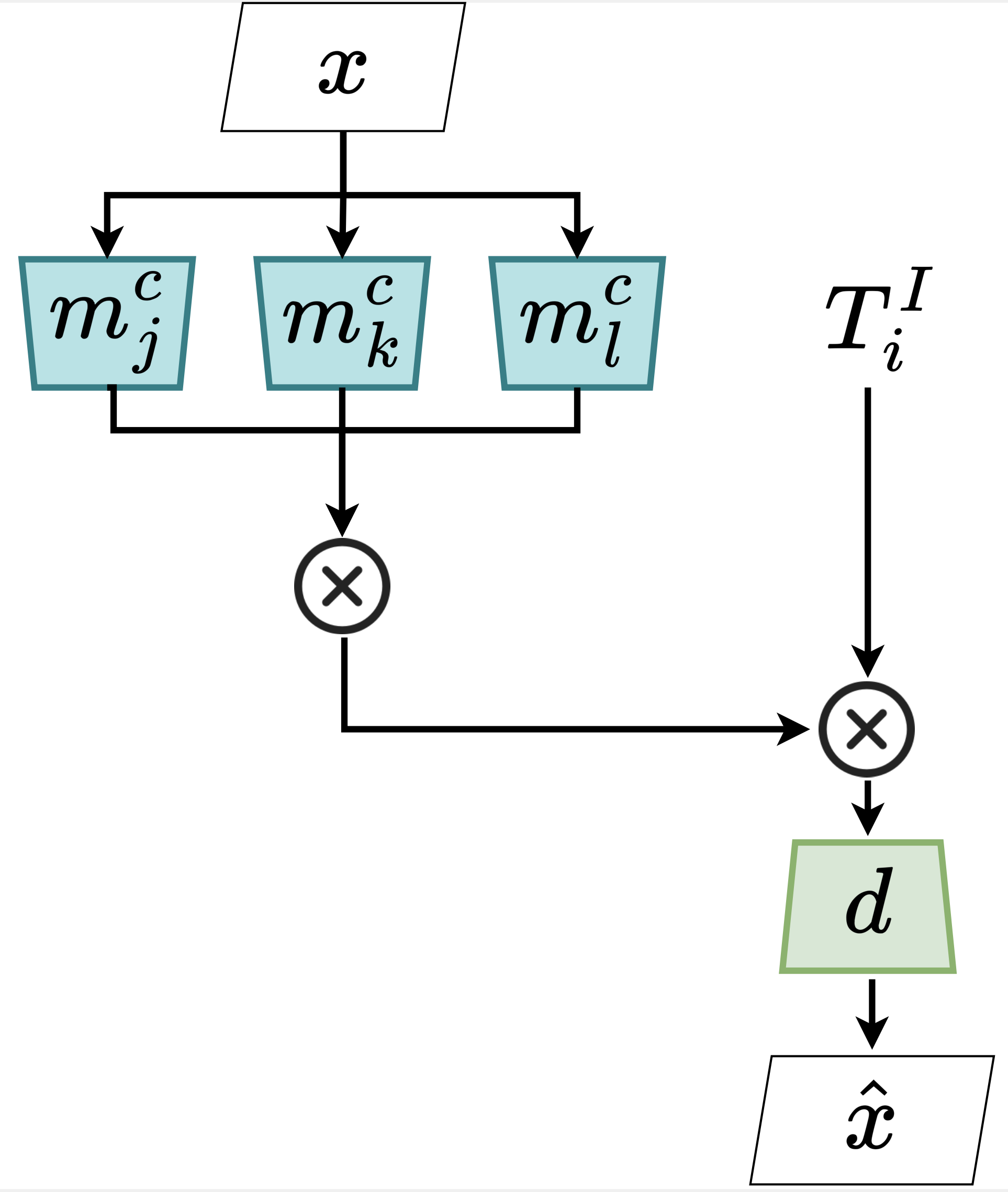
Hamed Damirchi, Forest Agostinelli, Pooyan Jamshidi
Workshop on Effective Representations, Abstractions, and Priors for Robot Learning (RAP4Robots at ICRA’23)
Abstract
Monolithic neural networks that make use of a single set of weights to learn useful representations for downstream tasks explicitly dismiss the compositional nature of data generation processes. This characteristic exists in data where every instance can be regarded as the combination of an identity concept, such as the shape of an object, combined with modifying concepts, such as orientation, color, and size. The dismissal of compositionality is especially detrimental in robotics, where state estimation relies heavily on the compositional nature of physical mechanisms (e.g., rotations and transformations) to model interactions. To accommodate this data characteristic, modular networks have been proposed. However, a lack of structure in each module's role, and modular network-specific issues such as module collapse have restricted their usability. We propose a modular network architecture that accommodates the mentioned decompositional concept by proposing a unique structure that splits the modules into predetermined roles. Additionally, we provide regularizations that improve the resiliency of the modular network to the problem of module collapse while improving the decomposition accuracy of the model.
Md Abir Hossen, Sonam Kharade, Bradley Schmerl, Javier Cámara, Jason M. O'Kane, Ellen C. Czaplinski, Katherine A. Dzurilla, David Garlan, and Pooyan Jamshidi
IEEE Robotics and Automation Letters (RA-L -> iROS'23)
Abstract
Robotic systems have several subsystems that possess a huge combinatorial configuration space and hundreds or even thousands of possible software and hardware configuration options interacting non-trivially. The configurable parameters can be tailored to target specific objectives, but when incorrectly configured, can cause functional faults. Finding the root cause of such faults is challenging due to the exponentially large configuration space and the dependencies between the robot's configuration settings and performance. This paper proposes CaRE, a method for diagnosing the root cause of functional faults through the lens of causality, which abstracts the causal relationships between various configuration options and the robot's performance objectives. We demonstrate CaRE's efficacy by finding the root cause of the observed functional faults via CaRE and validating the diagnosed root cause, conducting experiments in both physical robots (Husky and Turtlebot 3) and in simulation (Gazebo). Furthermore, we demonstrate that the causal models learned from robots in simulation (simulating Husky in Gazebo) are transferable to physical robots across different platforms (Turtlebot 3).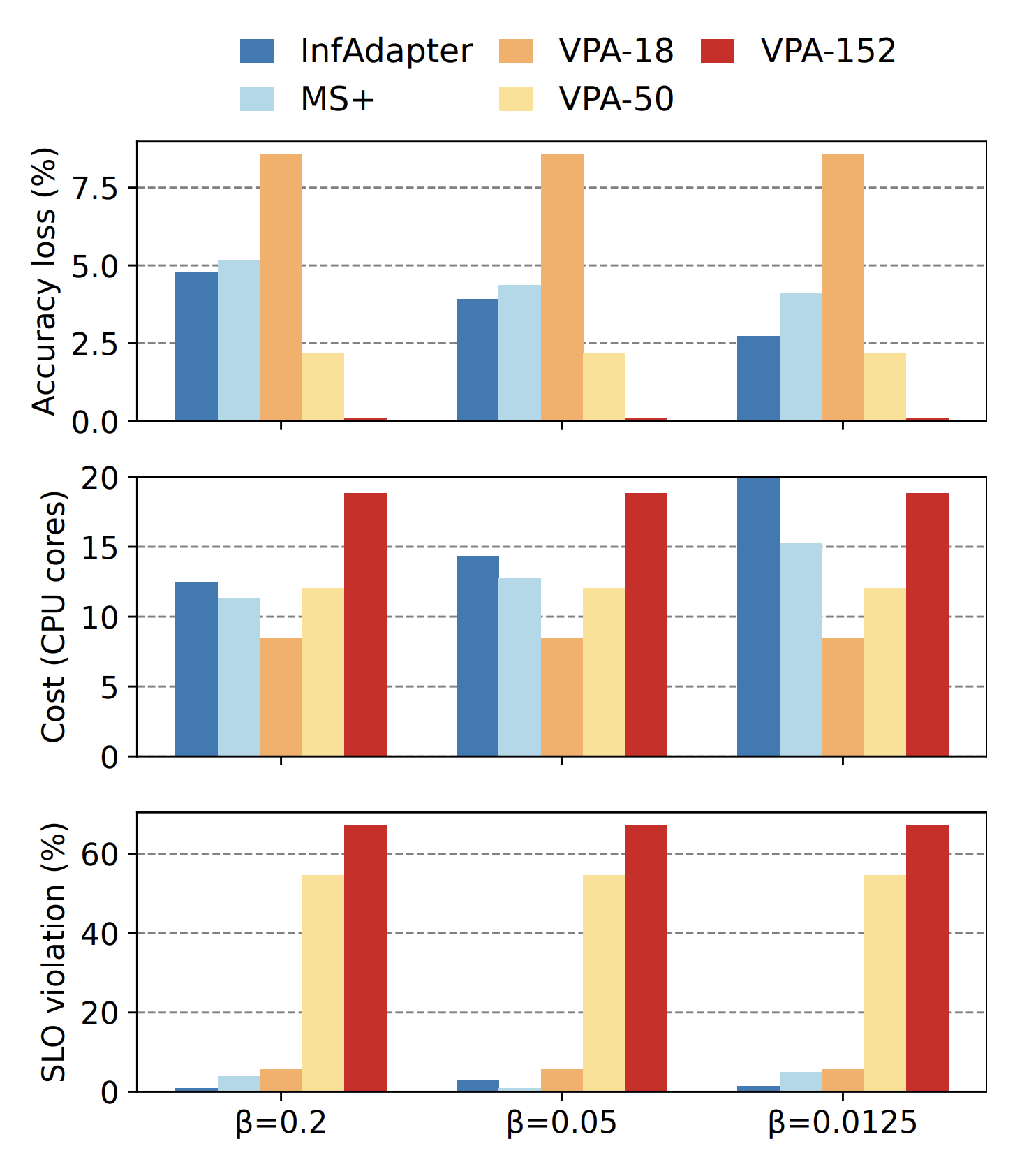
Mehran Salmani, Saeid Ghafouri, Alireza Sanaee, Kamran Razavi, Max Mühlhäuser, Joseph Doyle, Pooyan Jamshidi, Mohsen Sharifi
The 3rd Workshop on Machine Learning and Systems (EuroMLSys)
Abstract
The use of machine learning (ML) inference for various applications is growing drastically. ML inference services engage with users directly, requiring fast and accurate responses. Moreover, these services face dynamic workloads of requests, imposing changes in their computing resources. Failing to right-size computing resources results in either latency service level objectives (SLOs) violations or wasted computing resources. Adapting to dynamic workloads considering all the pillars of accuracy, latency, and resource cost is challenging. In response to these challenges, we propose InfAdapter, which proactively selects a set of ML model variants with their resource allocations to meet latency SLO while maximizing an objective function composed of accuracy and cost. InfAdapter decreases SLO violation and costs up to 65% and 33%, respectively, compared to a popular industry autoscaler (Kubernetes Vertical Pod Autoscaler).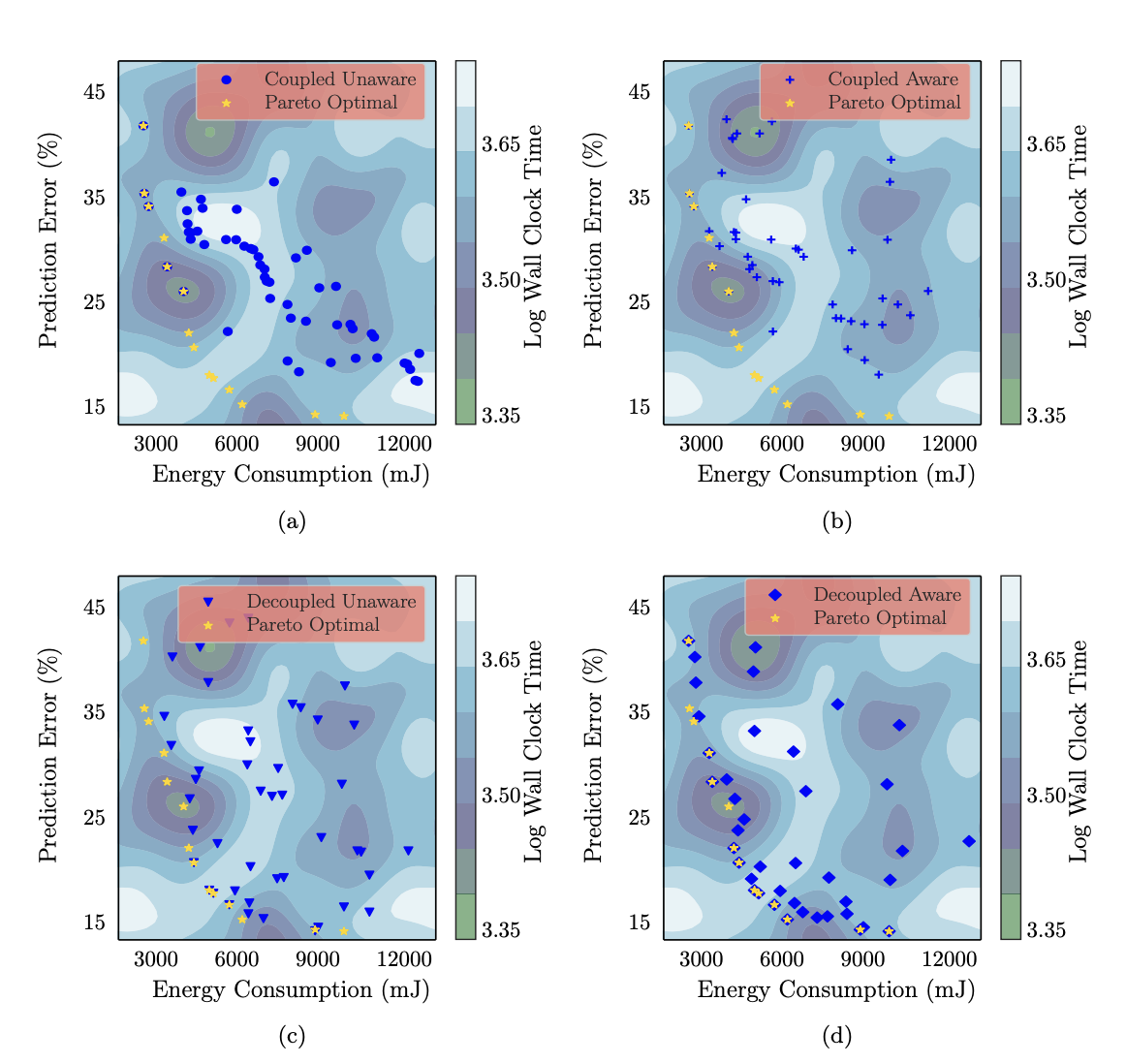
Shahriar Iqbal, Jianhai Su, Lars Kotthoff, Pooyan Jamshidi
Journal of Artificial Intelligence Research (JAIR)
Abstract
The design of machine learning systems often requires trading off different objectives, for example, prediction error and energy consumption for deep neural networks (DNNs). Typically, no single design performs well in all objectives; therefore, finding Pareto-optimal designs is of interest. The search for Pareto-optimal designs involves evaluating designs in an iterative process, and the measurements are used to evaluate an acquisition function that guides the search process. However, measuring different objectives incurs different costs. For example, the cost of measuring the prediction error of DNNs is orders of magnitude higher than that of measuring the energy consumption of a pre-trained DNN, as it requires re-training the DNN. Current state-of-the-art methods do not consider this difference in objective evaluation cost, potentially incurring expensive evaluations of objective functions in the optimization process. In this paper, we develop a novel decoupled and cost-aware multi-objective optimization algorithm, we call Flexible Multi-Objective Bayesian Optimization (FlexiBO) to address this issue. FlexiBO weights the improvement of the hypervolume of the Pareto region by the measurement cost of each objective to balance the expense of collecting new information with the knowledge gained through objective evaluations, preventing us from performing expensive measurements for little to no gain. We evaluate FlexiBO on seven state-of-the-art DNNs for image recognition, natural language processing (NLP), and speech-to-text translation. Our results indicate that, given the same total experimental budget, FlexiBO discovers designs with 4.8% to 12.4% lower hypervolume error than the best method in state-of-the-art multi-objective optimization.2022
Mohammadamin Abedi, Yani Ioannou, Pooyan Jamshidi, and Hadi Hemmati
Arxiv
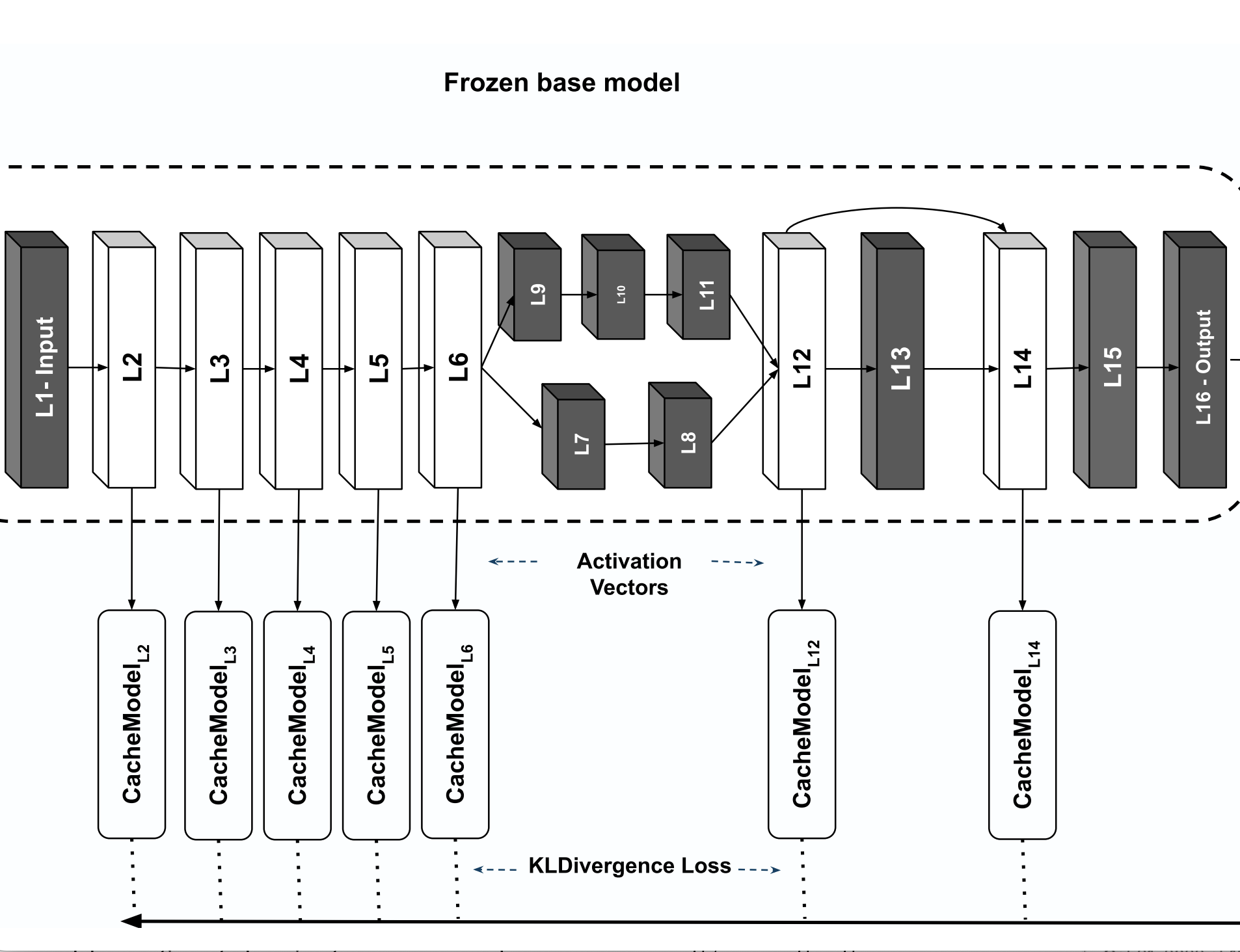
Abstract
Deep Neural Networks (DNNs) have become an essential component in many application domains including web-based services. A variety of these services require high throughput and (close to) real-time features, for instance, to respond or react to users' requests or to process a stream of incoming data on time. However, the trend in DNN design is toward larger models with many layers and parameters to achieve more accurate results. Although these models are often pre-trained, the computational complexity in such large models can still be relatively significant, hindering low inference latency. Implementing a caching mechanism is a typical systems engineering solution for speeding up a service response time. However, traditional caching is often not suitable for DNN-based services. In this paper, we propose an end-to-end automated solution to improve the performance of DNN-based services in terms of their computational complexity and inference latency. Our caching method adopts the ideas of self-distillation of DNN models and early exits. The proposed solution is an automated online layer caching mechanism that allows early exiting of a large model during inference time if the cache model in one of the early exits is confident enough for final prediction. One of the main contributions of this paper is that we have implemented the idea as an online caching, meaning that the cache models do not need access to training data and perform solely based on the incoming data at run-time, making it suitable for applications using pre-trained models. Our experiments results on two downstream tasks (face and object classification) show that, on average, caching can reduce the computational complexity of those services up to 58% (in terms of FLOPs count) and improve their inference latency up to 46% with low to zero reduction in accuracy.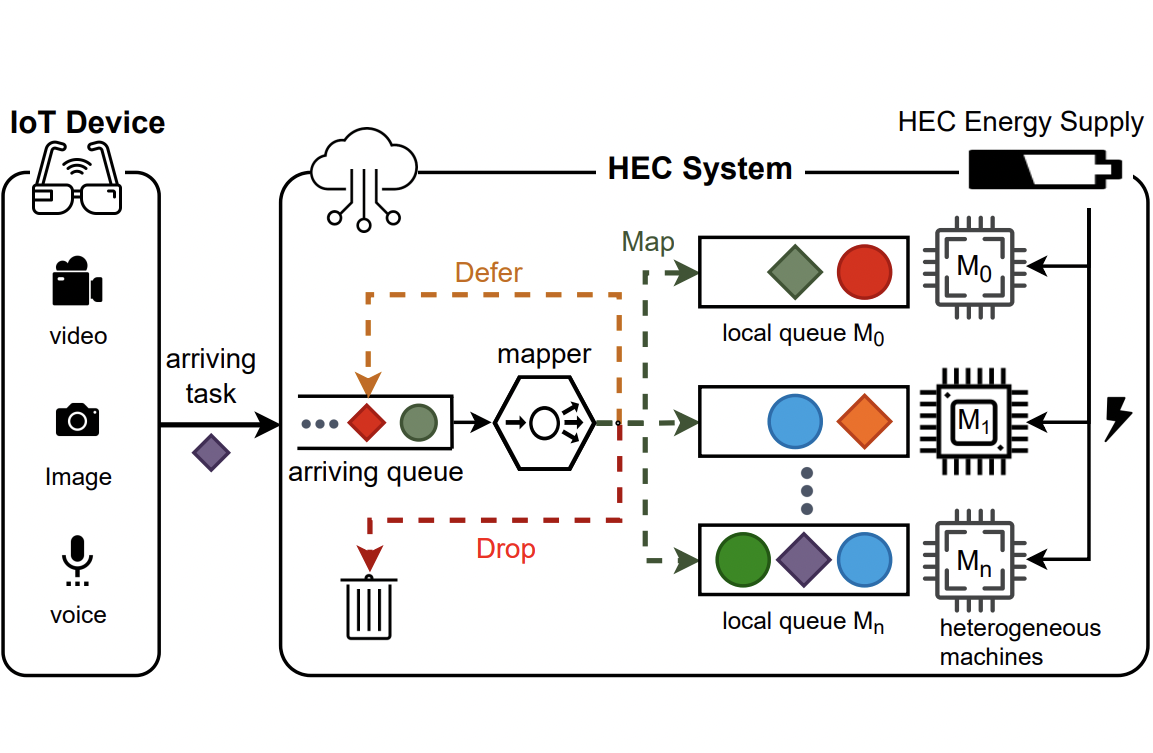
Ali Mokhtari, Abir Hossen, Pooyan Jamshidi, Mohsen Amini Salehi
International Conference on Cloud Computing (IEEE CLOUD)
Abstract
Edge computing enables smart IoT-based systems via concurrent and continuous execution of latency-sensitive machine learning (ML) applications. These edge-based machine learning systems are often battery-powered (i.e., energy-limited). They use heterogeneous resources with diverse computing performance (e.g., CPU, GPU, and/or FPGAs) to fulfill the latency constraints of ML applications. The challenge is to allocate user requests for different ML applications on the Heterogeneous Edge Computing Systems (HEC) with respect to both the energy and latency constraints of these systems. To this end, we study and analyze resource allocation solutions that can increase the on-time task completion rate while considering the energy constraint. Importantly, we investigate edge-friendly (lightweight) multi-objective mapping heuristics that do not become biased toward a particular application type to achieve the objectives; instead, the heuristics consider fairness across the concurrent ML applications in their mapping decisions. Performance evaluations demonstrate that the proposed heuristic outperforms widely-used heuristics in heterogeneous systems in terms of the latency and energy objectives, particularly, at low to moderate request arrival rates. We observed 8.9% improvement in on-time task completion rate and 12.6% in energy-saving without imposing any significant overhead on the edge system.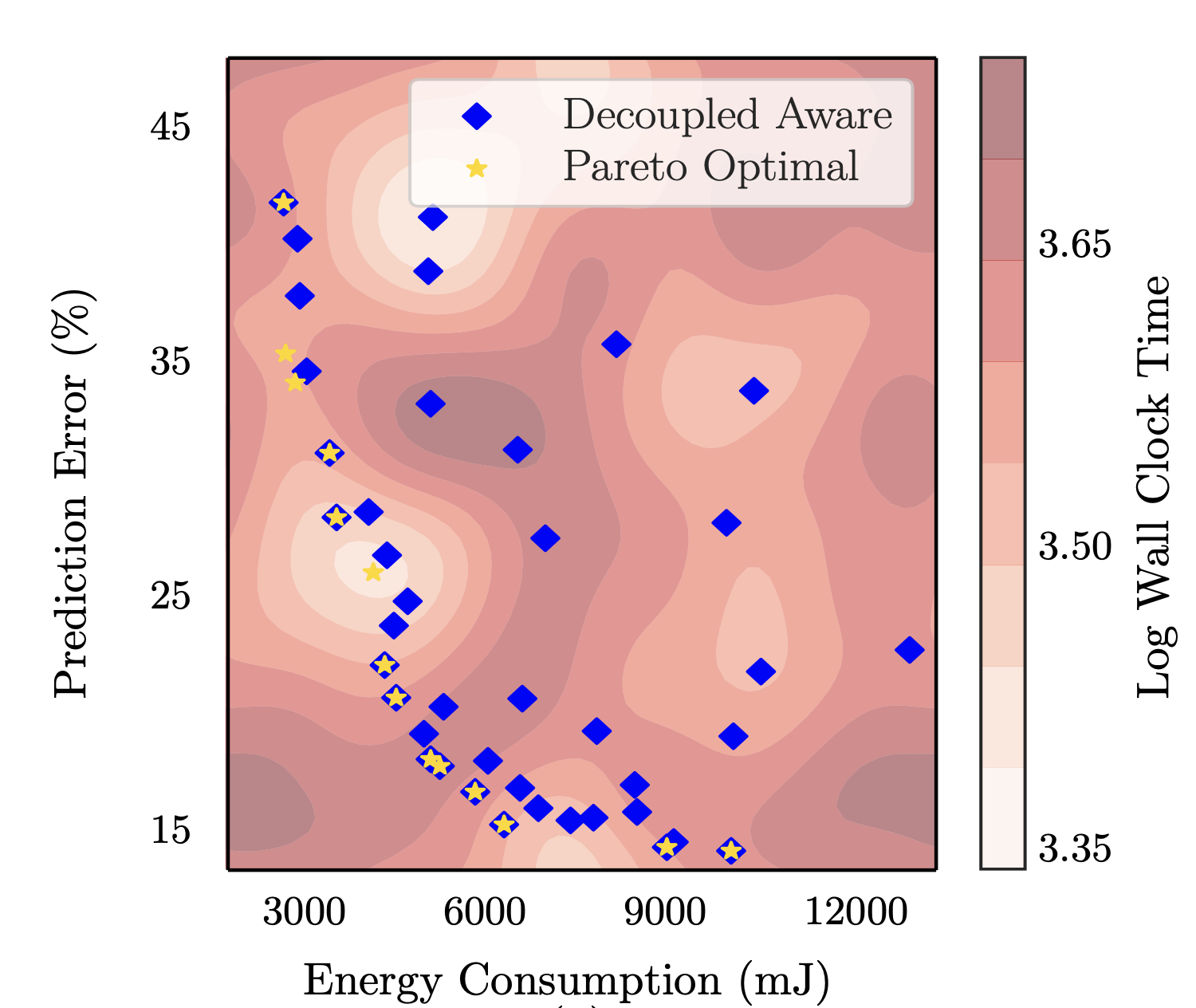
Shahriar Iqbal, Jianhai Su, Lars Kotthoff, Pooyan Jamshidi
International Conference on Automated Machine Learning (AutoML 2022)
Abstract
Machine learning system design frequently necessitates balancing multiple objectives, such as prediction error and energy consumption for deep neural networks (DNNs). Typically, no single design performs well across all objectives; thus, finding Pareto-optimal designs is of interest. Measuring different objectives frequently incurs different costs; for example, measuring the prediction error of DNNs is significantly more expensive than measuring the energy consumption of a pre-trained DNN because it requires re-training the DNN. Current state-of-the-art methods do not account for this difference in objective evaluation cost, potentially wasting costly evaluations of objective functions for little information gain. To address this issue, we propose a novel cost-aware decoupled approach that weights the improvement of the hypervolume of the Pareto region by the measurement cost of each objective. We perform experiments on a of range of DNN applications for comprehensive evaluation of our approach.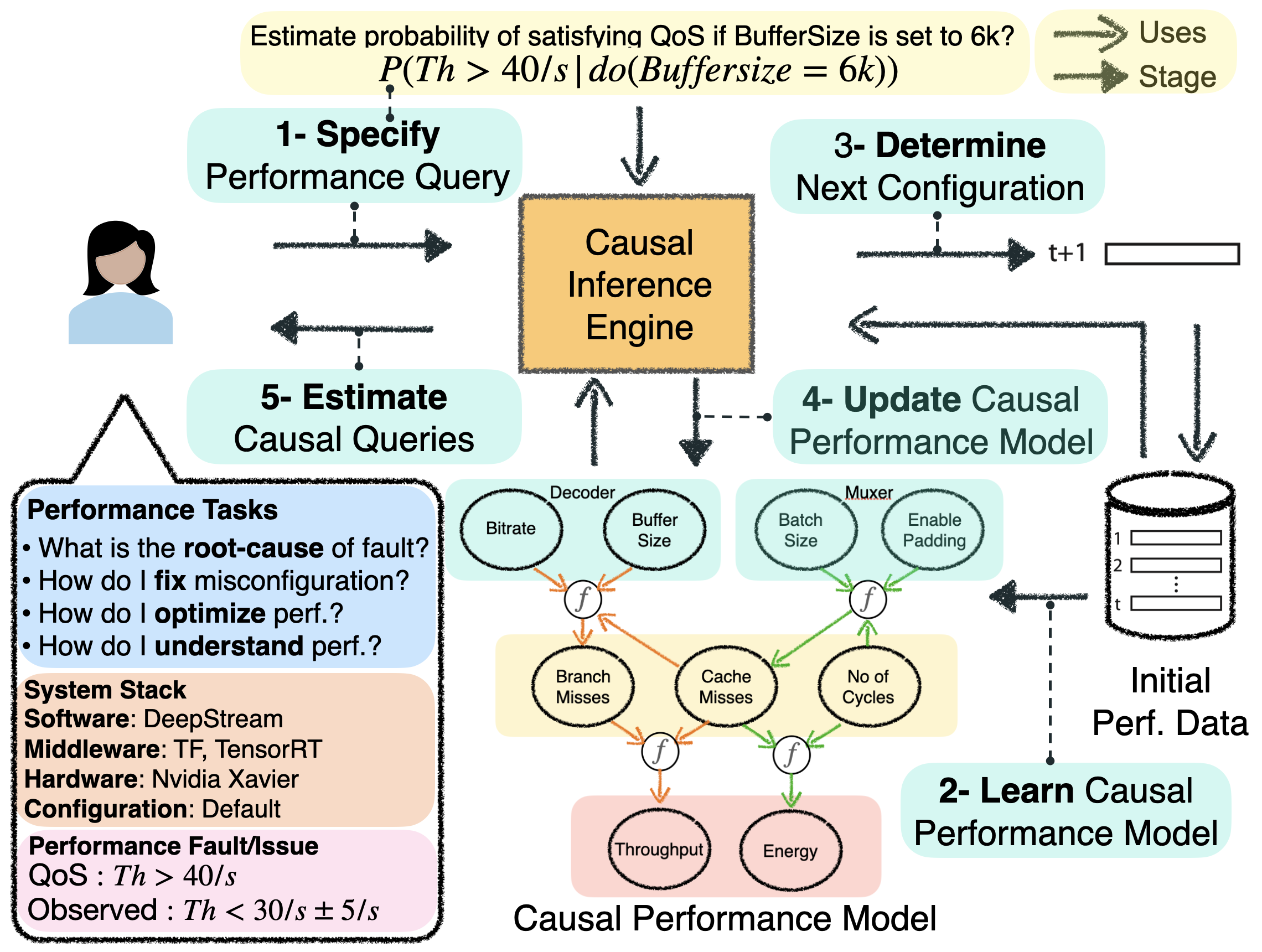
Shahriar Iqbal, Rahul Krishna, M.A. Javidian, Baishakhi Ray, Pooyan Jamshidi
European Conference on Computer Systems (EuroSys 2022)
Abstract
Modern computer systems are highly configurable, with the variability space sometimes larger than the number of atoms in the universe. Understanding and reasoning about the performance behavior of highly configurable systems, due to a vast variability space, is challenging. State-of-the-art methods for performance modeling and analyses rely on predictive machine learning models, therefore, they become (i) unreliable in unseen environments (e.g., different hardware, workloads), and (ii) produce incorrect explanations. To this end, we propose a new method, called Unicorn, which (a) captures intricate interactions between configuration options across the software-hardware stack and (b) describes how such interactions impact performance variations via causal inference. We evaluated Unicorn on six highly configurable systems, including three on-device machine learning systems, a video encoder, a database management system, and a data analytics pipeline. The experimental results indicate that Unicorn outperforms state-of-the-art performance optimization and debugging methods. Furthermore, unlike the existing methods, the learned causal performance models reliably predict performance for new environments.
Miguel Velez, Pooyan Jamshidi, Norbert Siegmund, Sven Apel, Christian Kaestner
International Conference on Software Engineering (ICSE 2022)
Abstract
Determining whether a configurable software system has a performance bug or it was misconfigured is often challenging. While there are numerous debugging techniques that can support developers in this task, there is limited empirical evidence of how useful the techniques are to address the actual needs that developers have when debugging the performance of configurable software systems; most techniques are often evaluated in terms of technical accuracy instead of their usability. In this paper, we take a human-centered approach to identify, design, implement, and evaluate a solution to support developers in the process of debugging the performance of configurable software systems. We first conduct an exploratory study with $19$ developers to identify the information needs that developers have during this process. Subsequently, we design and implement a tailored tool, adapting techniques from prior work, to support those needs. Two user studies, with a total of $20$ developers, validate and confirm that the information that we provide helps developers debug the performance of configurable software systems.2021
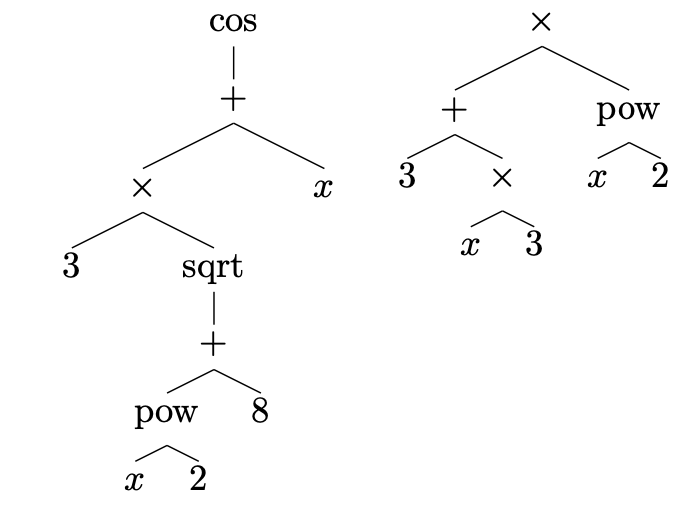
Kimia Noorbakhsh, Modar Sulaiman, Mahdi Sharifi, Kallol Roy, Pooyan Jamshidi
Arxiv
Abstract
Solving symbolic mathematics has always been of in the arena of human ingenuity that needs compositional reasoning and recurrence. However, recent studies have shown that large-scale language models such as transformers are universal and surprisingly can be trained as a sequence-to-sequence task to solve complex mathematical equations. These large transformer models need humongous amounts of training data to generalize to unseen symbolic mathematics problems. In this paper, we present a sample efficient way of solving the symbolic tasks by first pretraining the transformer model with language translation and then fine-tuning the pretrained transformer model to solve the downstream task of symbolic mathematics. We achieve comparable accuracy on the integration task with our pretrained model while using around 1.5 orders of magnitude less number of training samples with respect to the state-of-the-art deep learning for symbolic mathematics. The test accuracy on differential equation tasks is considerably lower comparing with integration as they need higher order recursions that are not present in language translations. We pretrain our model with different pairs of language translations. Our results show language bias in solving symbolic mathematics tasks. Finally, we study the robustness of the fine-tuned model on symbolic math tasks against distribution shift, and our approach generalizes better in distribution shift scenarios for the function integration.
Mohammad Ali Javidian, Om Pandey, Pooyan Jamshidi
NeurIPS WHY-21 (invited for oral talk, 16% of the accepted papers)
Abstract
One of the most important problems in transfer learning is the task of domain adaptation, where the goal is to apply an algorithm trained in one or more source domains to a different (but related) target domain. This paper deals with domain adaptation in the presence of covariate shift while there exist invariances across domains. A main limitation of existing causal inference methods for solving this problem is scalability. To overcome this difficulty, we propose SCTL, an algorithm that avoids an exhaustive search and identifies invariant causal features across the source and target domains based on Markov blanket discovery. SCTL does not require to have prior knowledge of the causal structure, the type of interventions, or the intervention targets. There is an intrinsic locality associated with SCTL that makes SCTL practically scalable and robust because local causal discovery increases the power of computational independence tests and makes the task of domain adaptation computationally tractable. We show the scalability and robustness of SCTL for domain adaptation using synthetic and real data sets in low-dimensional and high-dimensional settings.
Miguel Velez, Pooyan Jamshidi, Norbert Siegmund, Sven Apel, Christian Kaestner
International Conference on Software Engineering (ICSE 2021)
Abstract
Performance-influence models can help stakeholders understand how and where configuration options and their interactions influence the performance of a system. With this understanding, stakeholders can debug performance and make deliberate configuration decisions. Current black-box techniques to build such models combine various sampling and learning strategies, resulting in trade offs between measurement effort, accuracy, and interpretability. We present Comprex, a white-box approach to build performance-influence models for configurable systems, combining insights of local measurements, dynamic taint analysis to track options in the implementation, compositionality, and compression of the configuration space, without using machine learning to extrapolate incomplete samples. Our evaluation on 4 widely-used open-source projects demonstrates that Comprex builds similarly accurate performance-influence models to the most accurate and expensive black-box approach, but at a reduced cost and with additional benefits from interpretable and local models.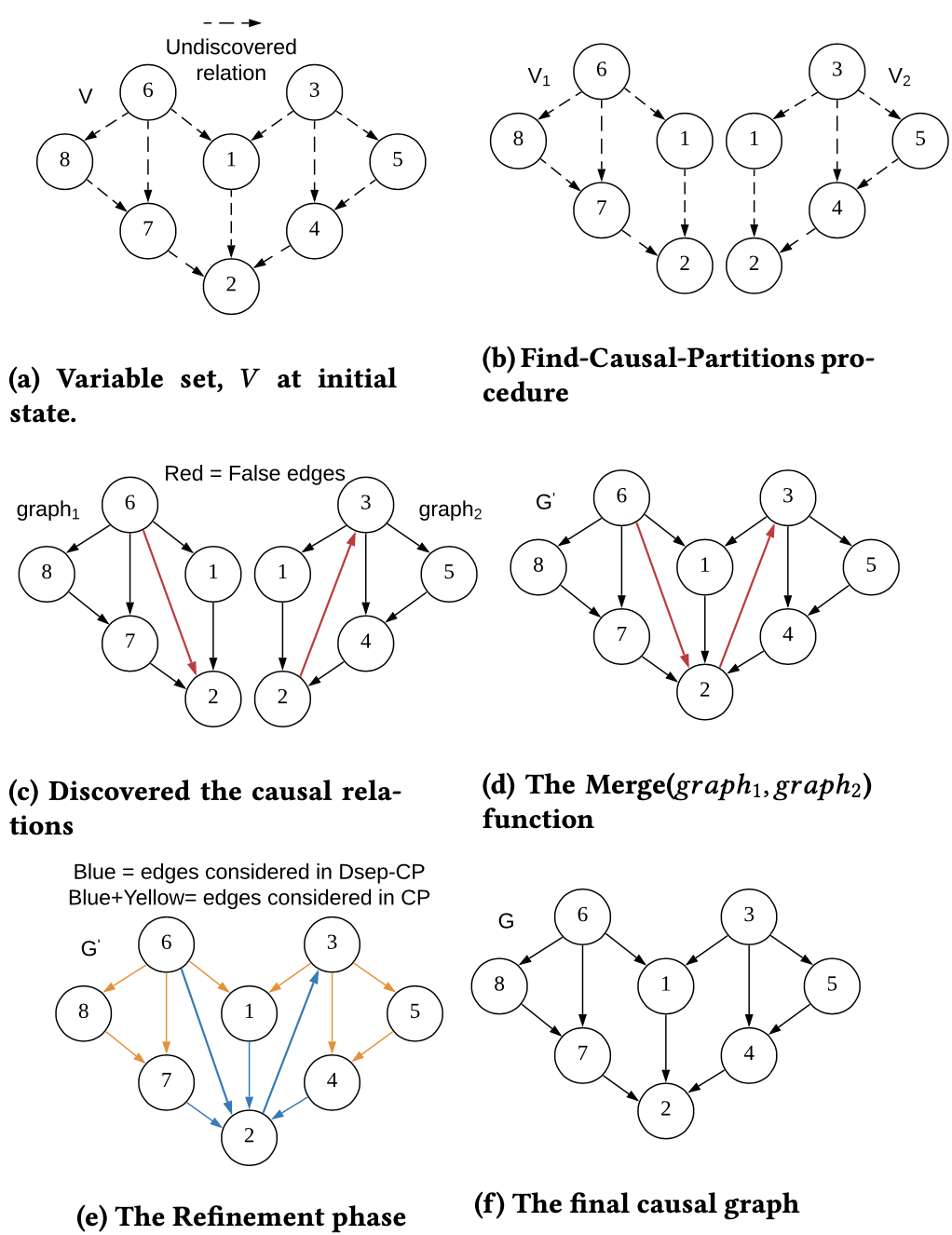
Md. Musfiqur Rahman, Ayman Rasheed, Md. Mosaddek Khan, Mohammad Ali Javidian, Pooyan Jamshidi, Md. Mamun-Or-Rashid
International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021)
Abstract
Causal structure discovery from observational data is fundamental to causal understanding of autonomous systems such as medical decision support systems, advertising campaign and self-driving cars. This is essential to solve well-known causal decision making and prediction problems associated with those real-world applications. Recently, recursive causal discovery algorithms have gained particular attention from the research community due to their ability to provide good results by using Conditional Independent (CI) tests from small sub-problems. However, each of such algorithms needs a refinement function to remove undesired causal relations of the discovered graphs. Notably, with the increase of the problem size, the computation cost (i.e., the number of CI-tests) of the refinement function makes an algorithm expensive to deploy in practice. In this paper, we propose a generic causal structure refinement strategy that can locate the undesired relations with a small number of CI-tests, and thus speeding up the algorithm for large and complex problems. We provide theoretical prove to confirm this. Finally, our empirical evaluation validates the dominance of our algorithm compared to the state-of-the-art algorithms in terms of completion time without compromising on the solution quality.2020
Shahriar Iqbal, Rahul Krishna, M.A. Javidian, Baishakhi Ray, Pooyan Jamshidi
NeurIPS 2020 (Workshop on ML for Systems)
Abstract
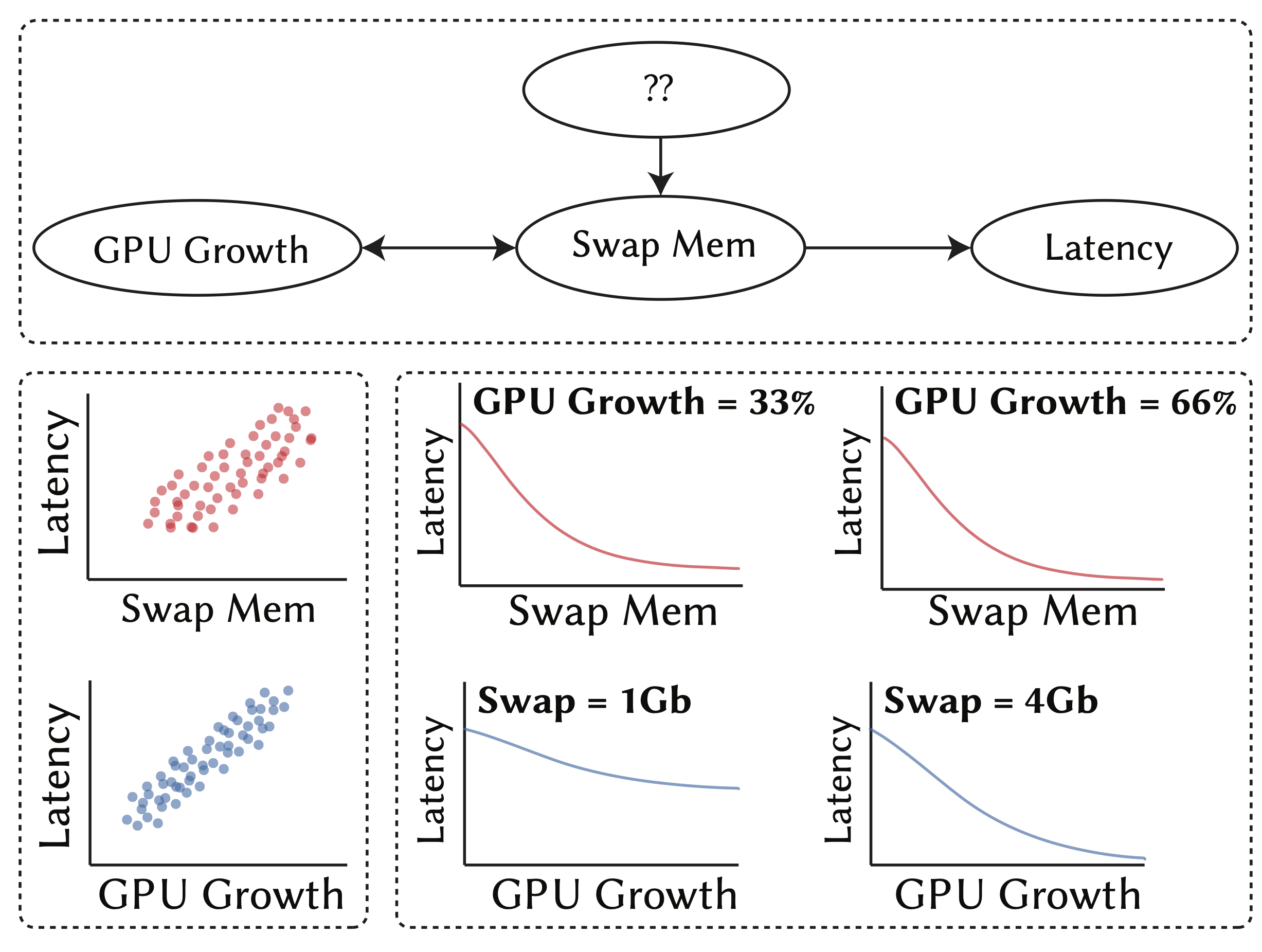
Modern computing platforms are highly-configurable with thousands of interacting configurations. However, configuring these systems is challenging. Erroneous configurations can cause unexpected non-functional faults. This paper proposes CADET (short for Causal Debugging Toolkit) that enables users to identify, explain, and fix the root cause of non-functional faults early and in a principled fashion. CADET builds a causal model by observing the performance of the system under different configurations. Then, it uses casual path extraction followed by counterfactual reasoning over the causal model to: (a) identify the root causes of non-functional faults, (b) estimate the effects of various configurable parameters on the performance objective(s), and (c) prescribe candidate repairs to the relevant configuration options to fix the non-functional fault. We evaluated CADET on 5 highly-configurable systems deployed on 3 NVIDIA Jetson systems-on-chip. We compare CADET with state-of-the-art configuration optimization and ML-based debugging approaches. The experimental results indicate that CADET can find effective repairs for faults in multiple non-functional properties with (at most) 17% more accuracy, 28% higher gain, and 40× speed-up than other ML-based performance debugging methods. Compared to multi-objective optimization approaches, CADET can find fixes (at most) 9× faster with comparable or better performance gain. Our case study of non-functional faults reported in NVIDIA's forum show that CADET can find 14 better repairs than the experts' advice in less than 30 minutes.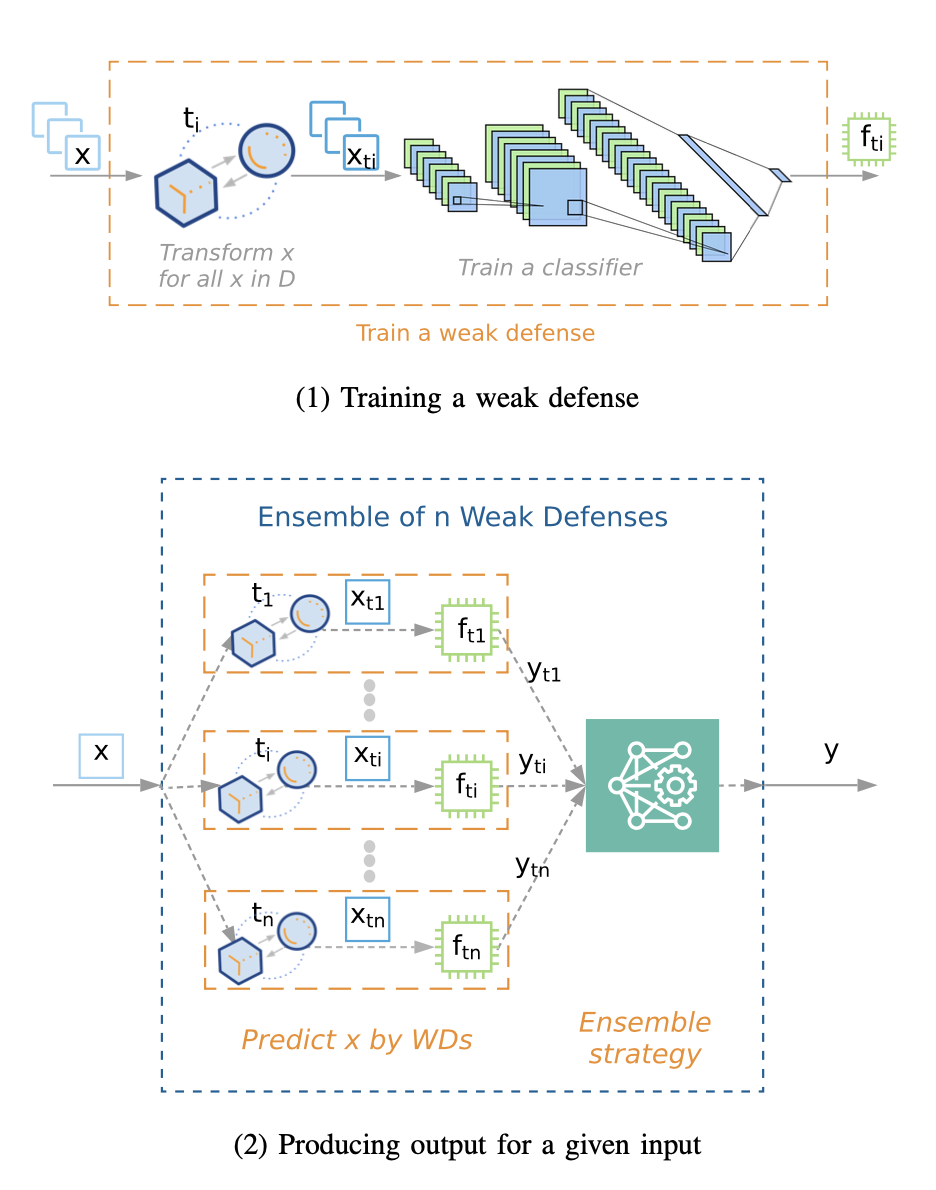
Ying Meng, Jianhai Su, Jason O’Kane, Pooyan Jamshidi
Arxiv
Abstract
There has been extensive research on developing defense techniques against adversarial attacks; however, they have been mainly designed for specific model families or application domains, therefore, they cannot be easily extended. Based on the design philosophy of ensemble of diverse weak defenses, we propose ATHENA---a flexible and extensible framework for building generic yet effective defenses against adversarial attacks. We have conducted a comprehensive empirical study to evaluate several realizations of ATHENA with four threat models including zero-knowledge, black-box, gray-box, and white-box. We also explain (i) why diversity matters, (ii) the generality of the defense framework, and (iii) the overhead costs incurred by ATHENA.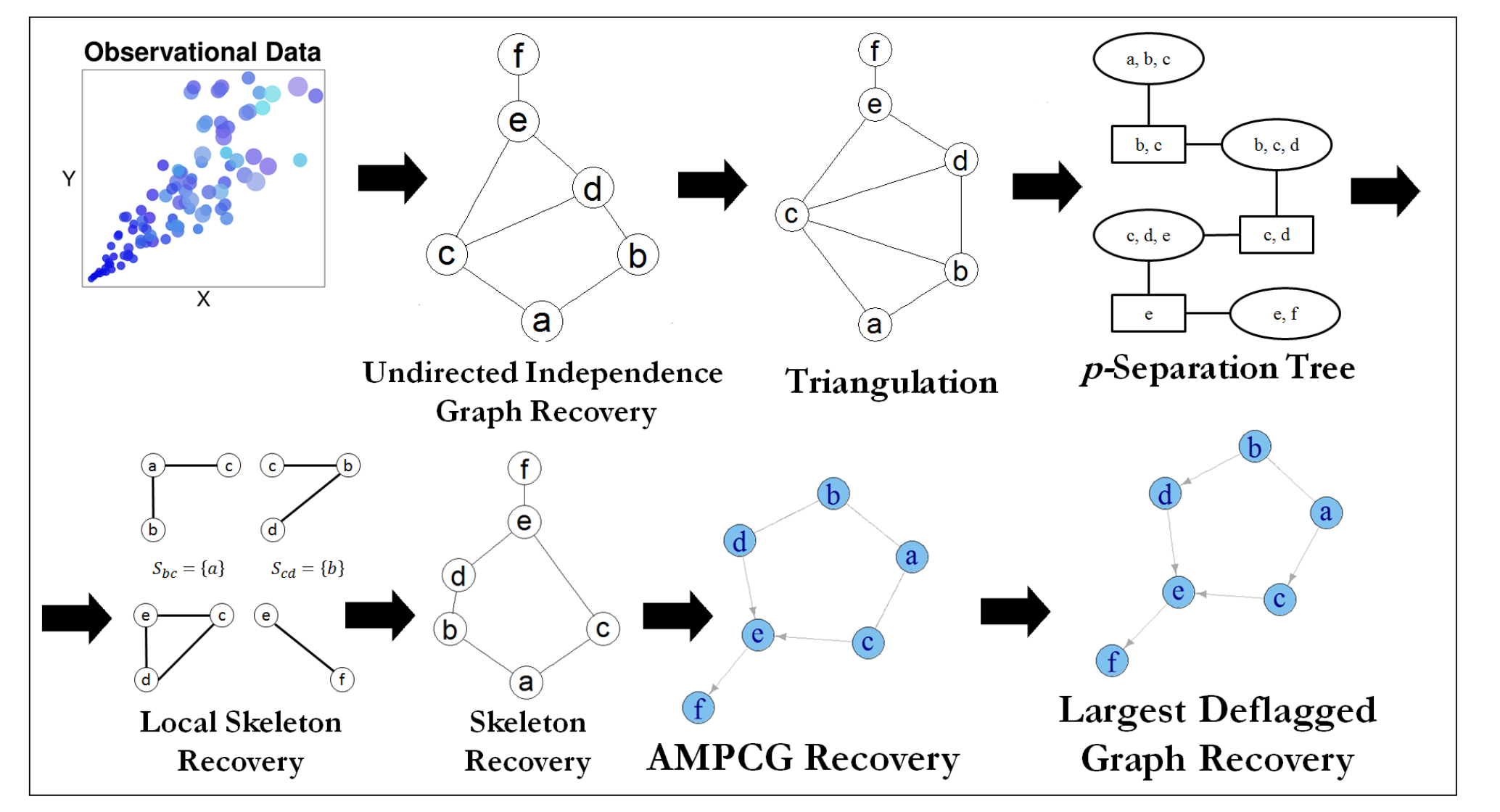
Mohammad Ali Javidian, Marco Valtorta, Pooyan Jamshidi
Journal of Artificial Intelligence Research (JAIR)
Abstract
We address the problem of finding a minimal separator in an Andersson–Madigan–Perlmanchain graph (AMP CG), namely, finding a set of nodes that separates a given non-adjacent pair of nodes such that no proper subset of separates that pair. We analyzeseveral versions of this problem and offerpolynomial timealgorithms for each. These include finding a minimal separator from a restricted set of nodes, finding a minimal sep-arator for two given disjoint sets, and testing whether a given separator is minimal. Weprovide an extension of the decomposition approach for learning Bayesian networks (BNs)proposed by (Xie et al., 2006) to learn AMP CGs, which include BNs as a special case, under the faithfulness assumption and prove its correctness using the minimal separatorresults. The advantages of this decomposition approach hold in the more general setting:reduced complexity and increased power of computational independence tests. In addition, we show that the PC-like algorithm isorder-dependent, in the sense that the output candepend on the order in which the variables are given. We propose two modifications of thePC-like algorithm that remove part or all of this order-dependence. Simulations under avariety of settings demonstrate the competitive performance of our decomposition-basedmethod, called LCD-AMP, in comparison with the (modified version of) PC-like algorithm. In fact, the decomposition-based algorithm usually outperforms the PC-like algorithm. We empirically show that the results of both algorithms are more accurate and stable whenthe sample size is reasonably large and the underlying graph is sparse.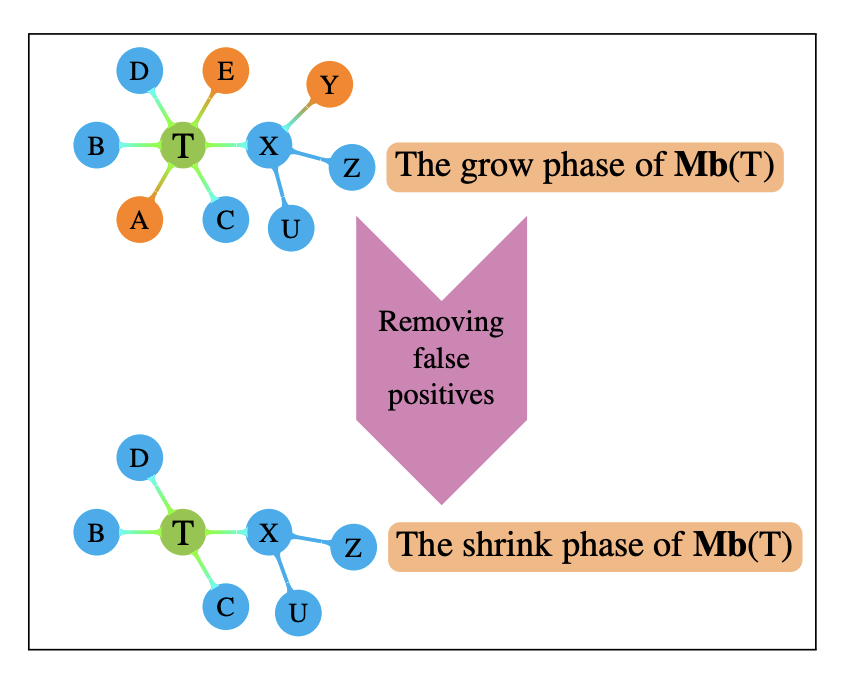
Mohammad Ali Javidian, Marco Valtorta, Pooyan Jamshidi
Conference on Uncertainty in Artificial Intelligence (UAI 2020)
Abstract
This paper provides a graphical characterization of Markov blankets in chain graphs (CGs) under the Lauritzen-Wermuth-Frydenberg (LWF) interpretation. The characterization is different from the well-known one for Bayesian networks and generalizes it. We provide a novel scalable and sound algorithm for Markov blanket discovery in LWF CGs and prove that the Grow-Shrink algorithm, the IAMB algorithm, and its variants are still correct for Markov blanket discovery in LWF CGs under the same assumptions as for Bayesian networks. We provide a sound and scalable constraint-based framework for learning the structure of LWF CGs from faithful causally sufficient data and prove its correctness when the Markov blanket discovery algorithms in this paper are used. Our proposed algorithms compare positively/competitively against the state-of-the-art LCD (Learn Chain graphs via Decomposition) algorithm, depending on the algorithm that is used for Markov blanket discovery. Our proposed algorithms make a broad range of inference/learning problems computationally tractable and more reliable because they exploit locality.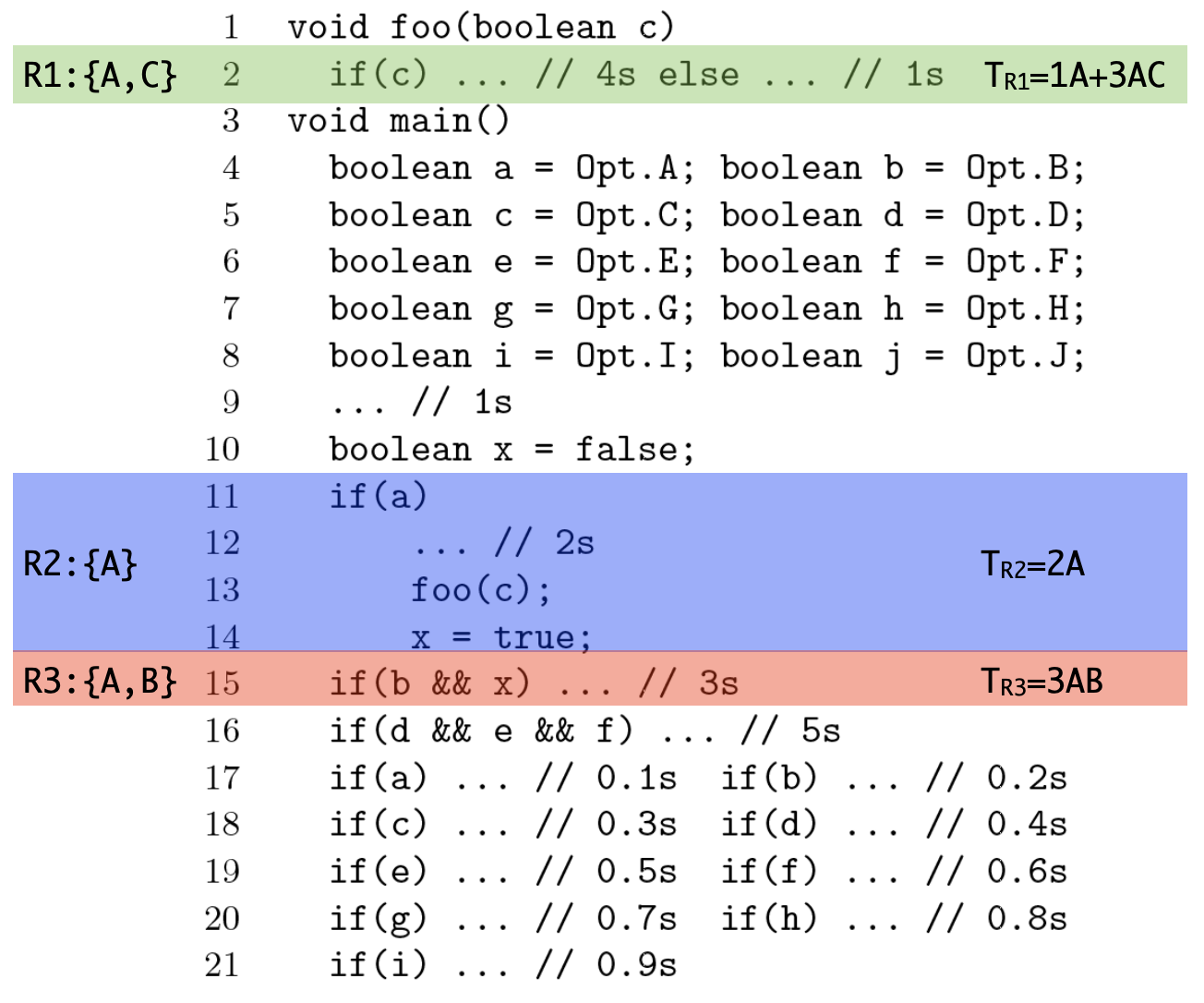
Miguel Velez, Pooyan Jamshidi, Florian Sattler, Norbert Siegmund, Sven Apel, Christian Kaestner
Springer Automated Software Engineering (AuSE)
Abstract
In configurable software systems, stakeholders are often interested in knowing how configuration options influence the performance of a system to facilitate, for example, the debugging and optimization processes of these systems. There are several black-box approaches to obtain this information, but they usually require a large number of samples to make accurate predictions, whereas the few existing white-box approaches impose limitations on the systems that they can analyze. This paper proposes ConfigCrusher, a white-box performance analysis that exploits several insights of configurable systems. ConfigCrusher employs a static data-flow analysis to identify how configuration options may influence control-flow decisions and instruments code regions corresponding to these decisions to dynamically analyze the influence of configuration options on the regions' performance. Our evaluation using 10 real-world configurable systems shows that ConfigCrusher is more efficient at building performance models that are similar to or more accurate than current state-of-the-art black-box and white-box approaches. Overall, this paper showcases the benefits and potential of white-box performance analyses to outperform black-box approaches and provide additional information for analyzing configurable systems.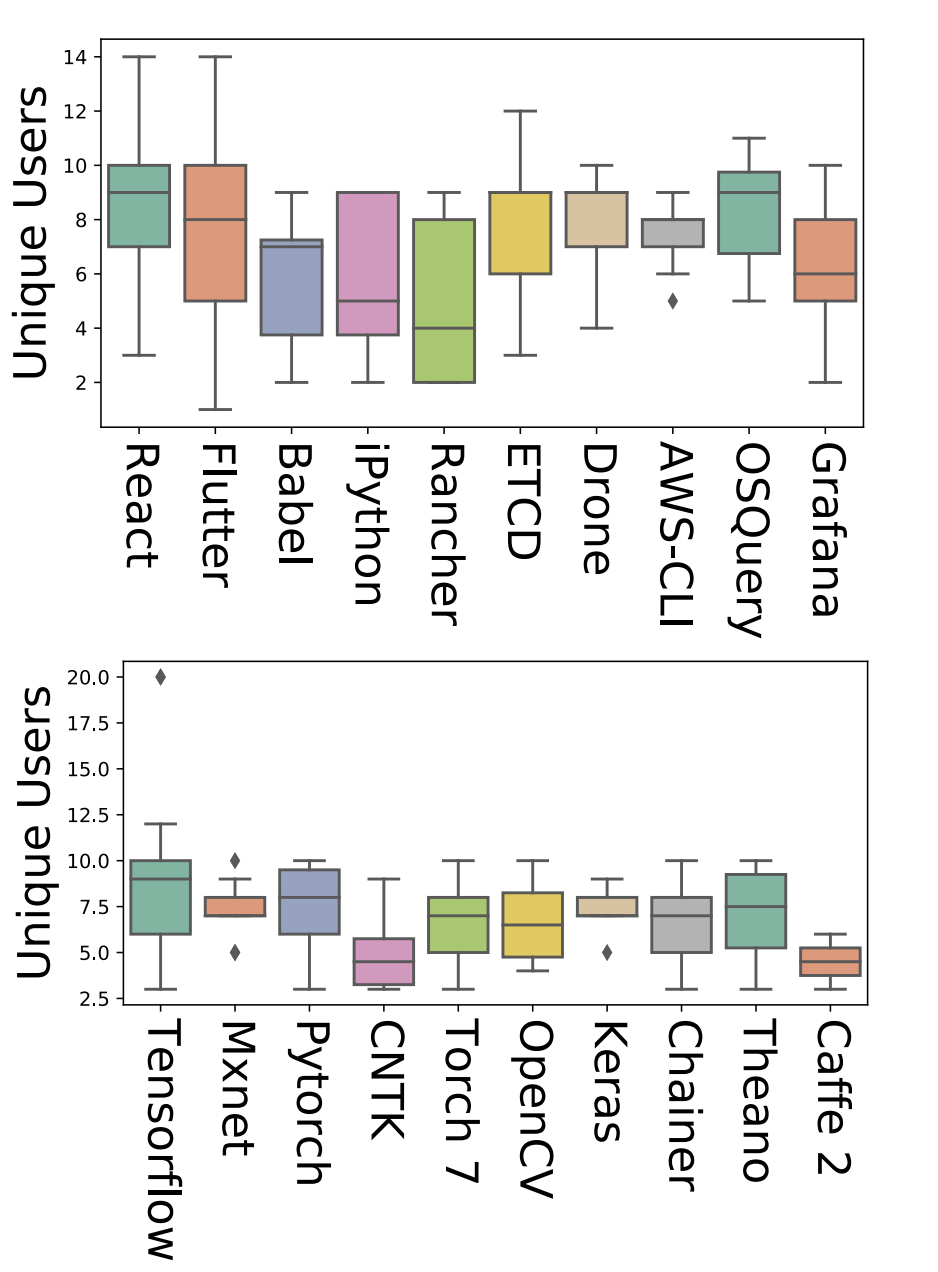
Yang Ren, Gregory Gay, Christian Kästner, Pooyan Jamshidi
Technical Report
Abstract
Modern systems are built using development frameworks. These frameworks have a major impact on how the resulting system executes, how configurations are managed, how it is tested, and how and where it is deployed. Machine learning (ML) frameworks and the systems developed using them differ greatly from traditional frameworks. Naturally, the issues that manifest in such frameworks may differ as well---as may the behavior of developers addressing those issues. We are interested in characterizing the system-related issues---issues impacting performance, memory and resource usage, and other quality attributes---that emerge in ML frameworks, and how they differ from those in traditional frameworks. We have conducted a moderate-scale exploratory study analyzing real-world system-related issues from 10 popular machine learning frameworks. Our findings offer implications for the development of machine learning systems, including differences in the frequency of occurrence of certain issue types, observations regarding the impact of debate and time on issue correction, and differences in the specialization of developers. We hope that this exploratory study will enable developers to improve their expectations, plan for risk, and allocate resources accordingly when making use of the tools provided by these frameworks to develop ML-based systems.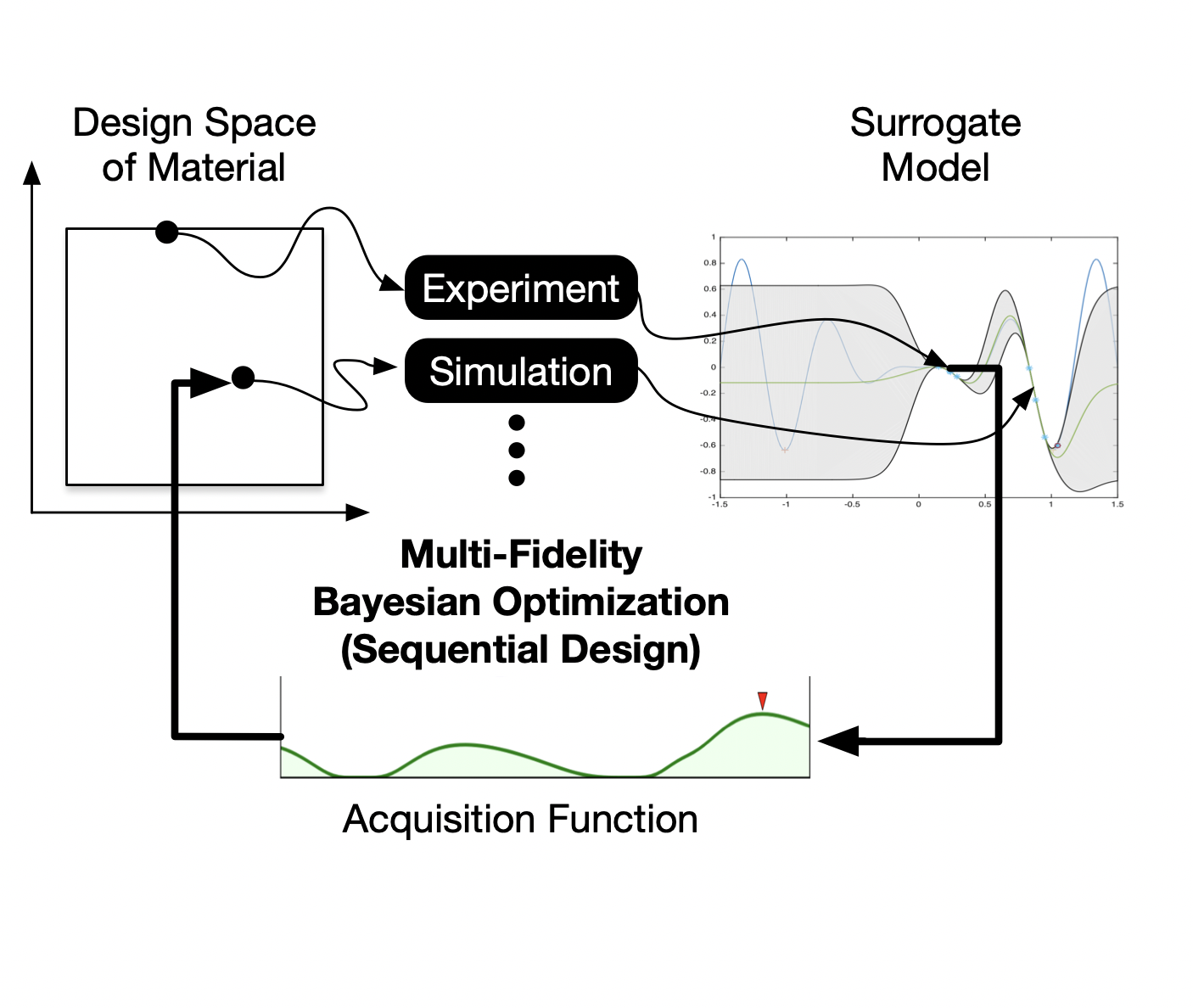
Katherine McCullough, Travis Williams, Kathleen Mingle, Pooyan Jamshidi, Jochen Lauterbach
Physical Chemistry Chemical Physics
Abstract
High throughput experimentation in heterogeneous catalysis provides an efficient solution to the generation of large datasets under reproducible conditions. Knowledge extraction from these datasets has mostly been performed using statistical methods, targeting the optimization of catalyst formulations. The combination of advanced machine learning methodologies with high-throughput experimentation has enormous potential to accelerate the predictive discovery of novel catalyst formulations that do not exist with current statistical design of experiments. This perspective describes selective examples ranging from statistical design of experiments for catalyst synthesis to genetic algorithms applied to catalyst optimization, and finally random forest machine learning using experimental data for the discovery of novel catalysts. Lastly, this perspective also provides an outlook on advanced machine learning methodologies as applied to experimental data for materials discovery.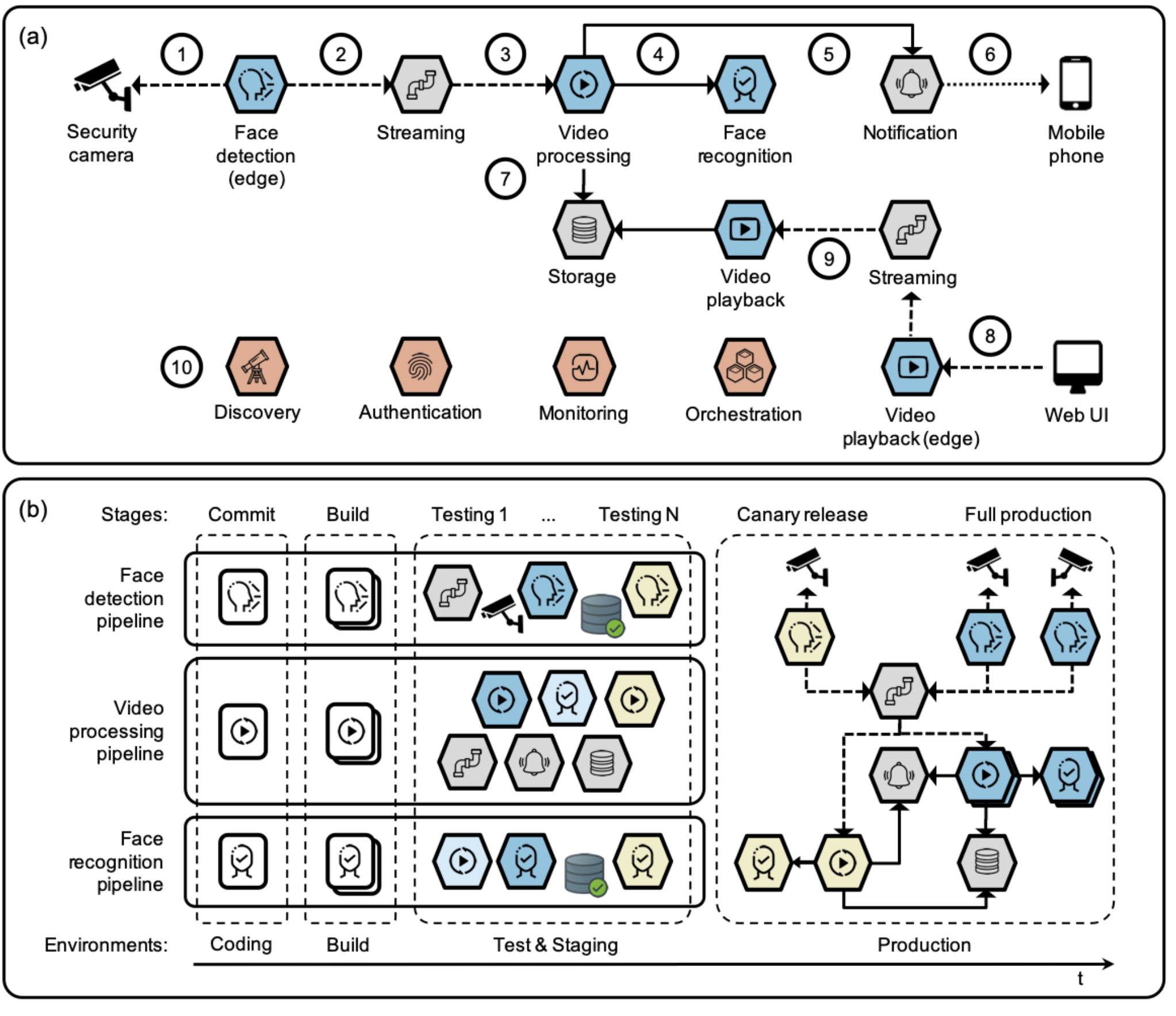
Nabor C. Mendonca, Pooyan Jamshidi, David Garlan, Claus Pahl
IEEE Software
Abstract
A self-adaptive system can dynamically monitor and adapt its behavior to preserve or enhance its quality attributes under uncertain operating conditions. This article identifies key challenges for the development of microservice applications as self-adaptive systems, using a cloud-based intelligent video surveillance application as a motivating example. It also suggests potential new directions for addressing most of the identified challenges by leveraging existing microservice practices and technologies.
Rahul Krishna, Vivek Nair, Pooyan Jamshidi, Tim Menzies
IEEE Transactions on Software Engineering (TSE)
Abstract
As software systems grow in complexity and the space of possible configurations increases exponentially, finding the near-optimal configuration of a software system becomes challenging. Recent approaches address this challenge by learning performance models based on a sample set of configurations. However, collecting enough sample configurations can be very expensive since each such sample requires configuring, compiling, and executing the entire system using a complex test suite. When learning on new data is too expensive, it is possible to use Transfer Learning to transfer old lessons to the new context. Traditional transfer learning has a number of challenges, specifically, (a) learning from excessive data takes excessive time, and (b) the performance of the models built via transfer can deteriorate as a result of learning from a poor source. To resolve these problems, we propose a novel transfer learning framework called BEETLE, which is a bellwether-based transfer learner that focuses on identifying and learning from the most relevant source from amongst the old data. This paper evaluates BEETLE with 57 different software configuration problems based on five software systems (a video encoder, an SAT solver, a SQL database, a high-performance C-compiler, and a streaming data analytics tool). In each of these cases, BEETLE found configurations that are as good as or better than those found by other state-of-the-art transfer learners while requiring only a fraction of the measurements needed by those other methods. Based on these results, we say that BEETLE is a new high-water mark in optimally configuring software.2019
Mohammad Ali Javidian, Marco Valtorta, Pooyan Jamshidi
Conference on Scalable Uncertainty Management (SUM 2019)
Abstract
This paper deals with multivariate regression chain graphs (MVR CGs), which were introduced by Cox and Wermuth [3,4] to represent linear causal models with correlated errors. We consider the PC-like algorithm for structure learning of MVR CGs, which is a constraint-based method proposed by Sonntag and Peña in [18]. We show that the PC-like algorithm is order-dependent, in the sense that the output can depend on the order in which the variables are given. This order-dependence is a minor issue in low-dimensional settings. However, it can be very pronounced in high-dimensional settings, where it can lead to highly variable results. We propose two modifications of the PC-like algorithm that remove part or all of this order-dependence. Simulations under a variety of settings demonstrate the competitive performance of our algorithms in comparison with the original PC-like algorithm in low-dimensional settings and improved performance in high-dimensional settings.
Pooyan Jamshidi, Javier Camara, Bradley Schmerl, Christian Kaestner, David Garlan
Software Engineering for Adaptive and Self-Managing Systems (SEAMS 2019)
Abstract
Modern cyber-physical systems (e.g., robotics systems) are typically composed of physical and software components, the characteristics of which are likely to change over time. Assumptions about parts of the system made at design time may not hold at run time, especially when a system is deployed for long periods (e.g., over decades). Self-adaptation is designed to find reconfigurations of systems to handle such run-time inconsistencies. Planners can be used to find and enact optimal reconfigurations in such an evolving context. However, for systems that are highly configurable, such planning becomes intractable due to the size of the adaptation space. To overcome this challenge, in this paper we explore an approach that (a) uses machine learning to find Pareto-optimal configurations without needing to explore every configuration and (b) restricts the search space to such configurations to make planning tractable. We explore this in the context of robot missions that need to consider task timeliness and energy consumption. An independent evaluation shows that our approach results in high-quality adaptation plans in uncertain and adversarial environments.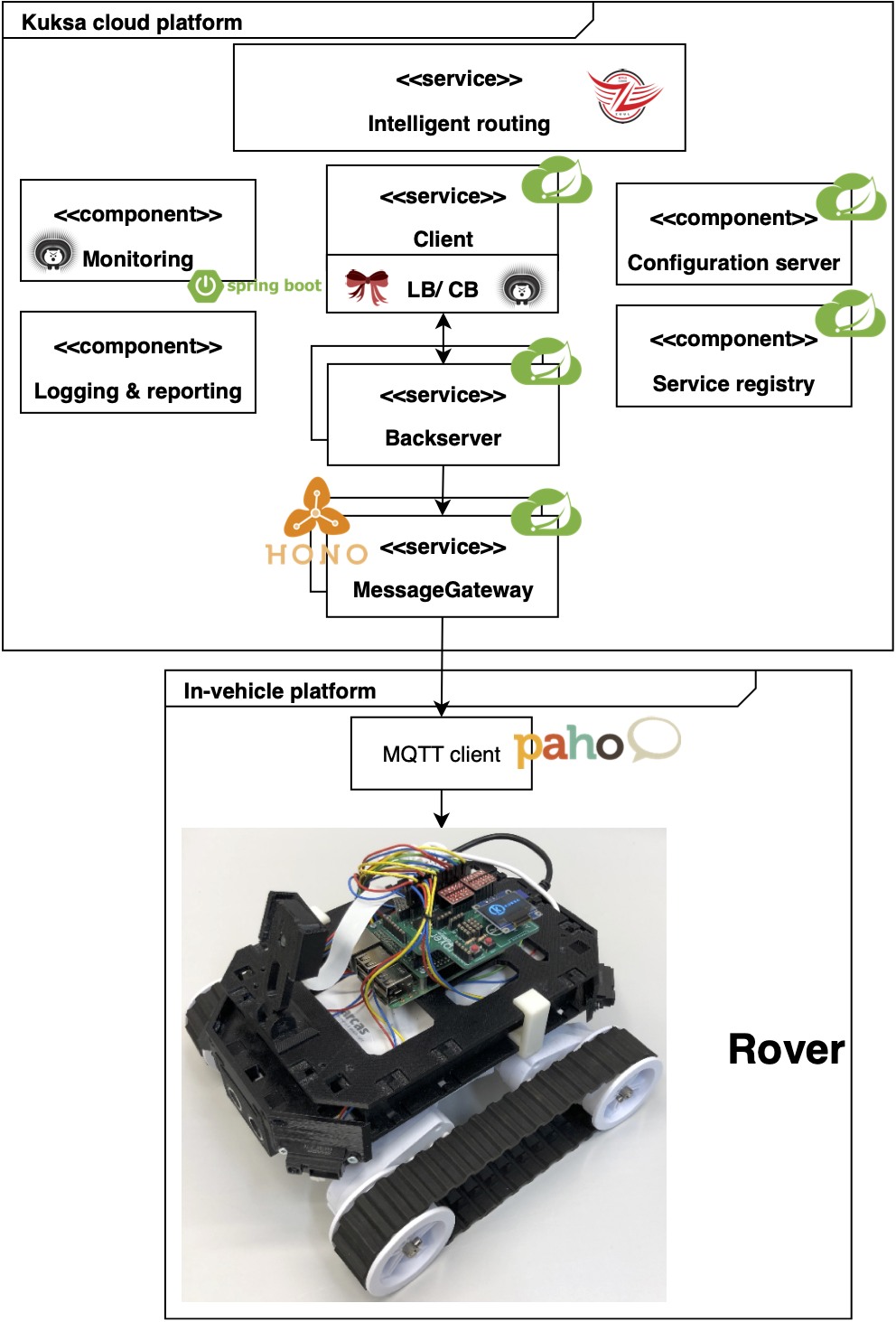
Ahmad Banijamali, Pooyan Jamshidi, Pasi Kuvaja, Markku Oivo
Product-Focused Software Process Improvement (PROFES 2019)
Abstract
Connecting vehicles to cloud platforms has enabled innovative business scenarios while raising new quality concerns, such as reliability and scalability, which must be addressed by research. Cloud-native architectures based on microservices are a recent approach to enable continuous delivery and to improve service reliability and scalability. We propose an approach for restructuring cloud platform architectures in the automotive domain into a microservices architecture. To this end, we adopted and implemented microservices patterns from literature to design the cloud-native automotive architecture and conducted a laboratory experiment to evaluate the reliability and scalability of microservices in the context of a real-world project in the automotive domain called Eclipse Kuksa. Findings indicated that the proposed architecture could handle the continuous software delivery over-the-air by sending automatic control messages to a vehicular setting. Different patterns enabled us to make changes or interrupt services without extending the impact to others. The results of this study provide evidences that microservices are a potential design solution when dealing with service failures and high payload on cloud-based services in the automotive domain.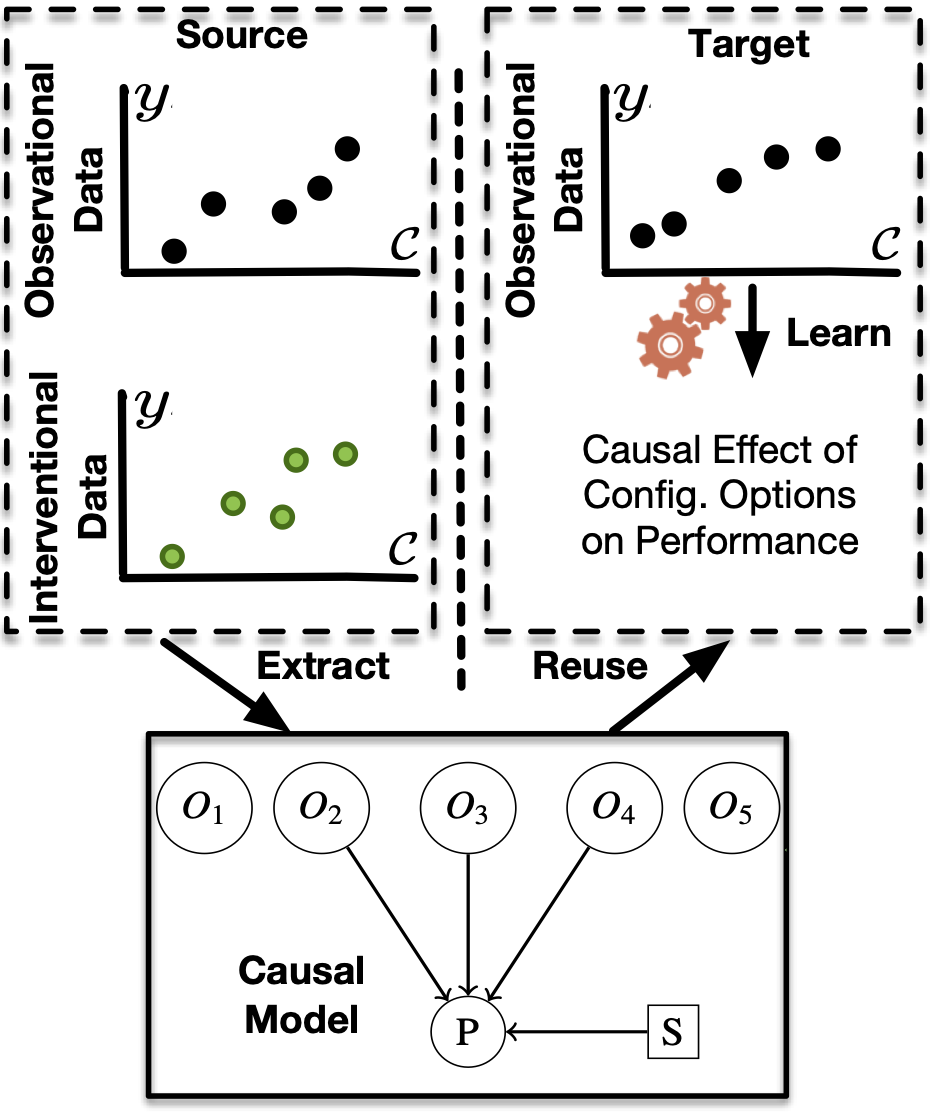
Mohammad Ali Javidian, Pooyan Jamshidi, Marco Valtorta
AAAI Conference on Artificial Intelligence (AAAI 2019)
Abstract
Modern systems (e.g., deep neural networks, big data analytics, and compilers) are highly configurable, which means they expose different performance behavior under different configurations. The fundamental challenge is that one cannot simply measure all configurations due to the sheer size of the configuration space. Transfer learning has been used to reduce the measurement efforts by transferring knowledge about performance behavior of systems across environments. Previously, research has shown that statistical models are indeed transferable across environments. In this work, we investigate identifiability and transportability of causal effects and statistical relations in highly-configurable systems. Our causal analysis agrees with previous exploratory analysis and confirms that the causal effects of configuration options can be carried over across environments with high confidence. We expect that the ability to carry over causal relations will enable effective performance analysis of highly-configurable systems.
Marcello M. Bersani, Francesco Marconi, Damian A. Tamburri, Andrea Nodari, Pooyan Jamshidi
Springer Journal of Big Data
Abstract
Big data architectures have been gaining momentum in recent years. For instance, Twitter uses stream processing frameworks like Apache Storm to analyse billions of tweets per minute and learn the trending topics. However, architectures that process big data involve many diferent components interconnected via semantically diferent connectors. Such complex architectures make possible refactoring of the applications a difcult task for software architects, as applications might be very diferent with respect to the initial designs. As an aid to designers and d evelopers, we developed OSTIA (Ordinary Static Topology Inference Analysis) that allows detecting the occurrence of common anti-patterns across big data architectures and exploiting software verifcation techniques on the elicited architectural models. This paper illustrates OSTIA and evaluates its uses and benefts on three industrial-scale case-studies.
Shahriar Iqbal, Lars Kotthoff, Pooyan Jamshidi
USENIX Operational Machine Learning (OpML 2019)
Abstract
Modern deep neural network (DNN) systems are highly configurable with large a number of options that significantly affect their non-functional behavior, for example inference time and energy consumption. Performance models allow to understand and predict the effects of such configuration options on system behavior, but are costly to build because of large configuration spaces. Performance models from one environment cannot be transferred directly to another; usually models are rebuilt from scratch for different environments, for example different hardware. Recently, transfer learning methods have been applied to reuse knowledge from performance models trained in one environment in another. In this paper, we perform an empirical study to understand the effectiveness of different transfer learning strategies for building performance models of DNN systems. Our results show that transferring information on the most influential configuration options and their interactions is an effective way of reducing the cost to build performance models in new environments.
J. Aldrich, J. Biswas, J. Camara, D. Garlan, A. Guha, J. Holtz, P. Jamshidi, C. Kaestner, C. Le Goues, A. Kabir, I. Ruchkin, S. Samuel, B. Schmerl, C. Steven Timperley, M. Veloso, I. Voysey
IEEE Software
Abstract
We developed model-based adaptation, an approach that leverages models of software and its environment to enable automated adaptation. The goal of our approach is to build long-lasting software systems that can effectively adapt to changes in their environment.
AM. Roth, N. Topin, P. Jamshidi, M. Veloso
Arxiv
Abstract
There is a growing desire in the field of reinforcement learning (and machine learning in general) to move from black-box models toward more interpretable AI. We improve interpretability of reinforcement learning by increasing the utility of decision tree policies learned via reinforcement learning. These policies consist of a decision tree over the state space, which requires fewer parameters to express than traditional policy representations. Existing methods for creating decision tree policies via reinforcement learning focus on accurately representing an action-value function during training, but this leads to much larger trees than would otherwise be required. To address this shortcoming, we propose a novel algorithm which only increases tree size when the estimated discounted future reward of the overall policy would increase by a sufficient amount. Through evaluation in a simulated environment, we show that its performance is comparable or superior to traditional tree-based approaches and that it yields a more succinct policy. Additionally, we discuss tuning parameters to control the tradeoff between optimizing for smaller tree size or for overall reward.2018
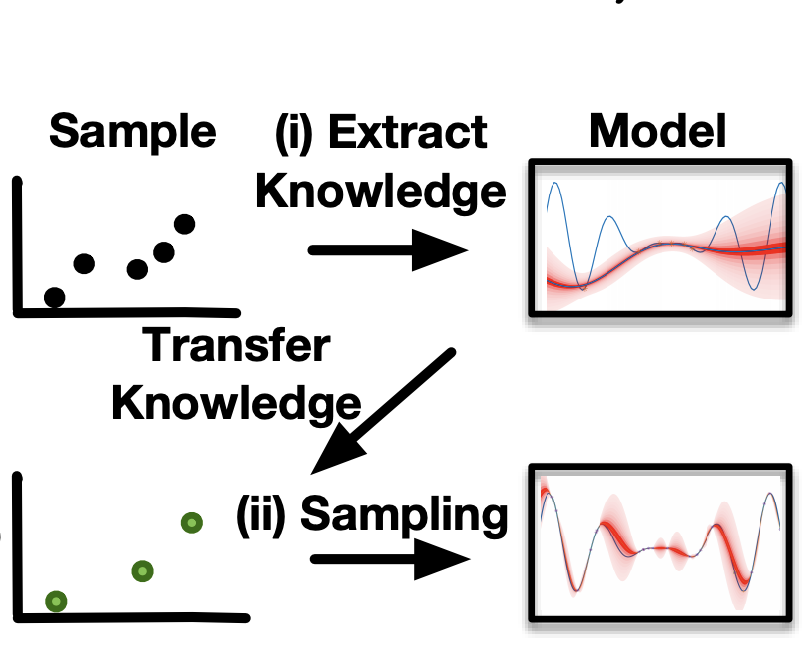
Pooyan Jamshidi, Miguel Velez, Christian Kaestner, Norbert Siegmund
Foundations of Software Engineering (FSE 2018)
Abstract
Most software systems provide options that allow users to tailor the system in terms of functionality and qualities. The increased flexibility raises challenges for understanding the configuration space and the effects of options and their interactions on performance and other non-functional properties. To identify how options and interactions affect the performance of a system, several sampling and learning strategies have been recently proposed. However, existing approaches usually assume a fixed environment (hardware, workload, software release) such that learning has to be repeated once the environment changes. Repeating learning and measurement for each environment is expensive and often practically infeasible. Instead, we pursue a strategy that transfers knowledge across environments but sidesteps heavyweight and expensive transfer-learning strategies. Based on empirical insights about common relationships regarding (i) influential options, (ii) their interactions, and (iii) their performance distributions, our approach, L2S (Learning to Sample), selects better samples in the target environment based on information from the source environment. It progressively shrinks and adaptively concentrates on interesting regions of the configuration space. With both synthetic benchmarks and several real systems, we demonstrate that L2S outperforms state of the art performance learning and transfer-learning approaches in terms of measurement effort and learning accuracy.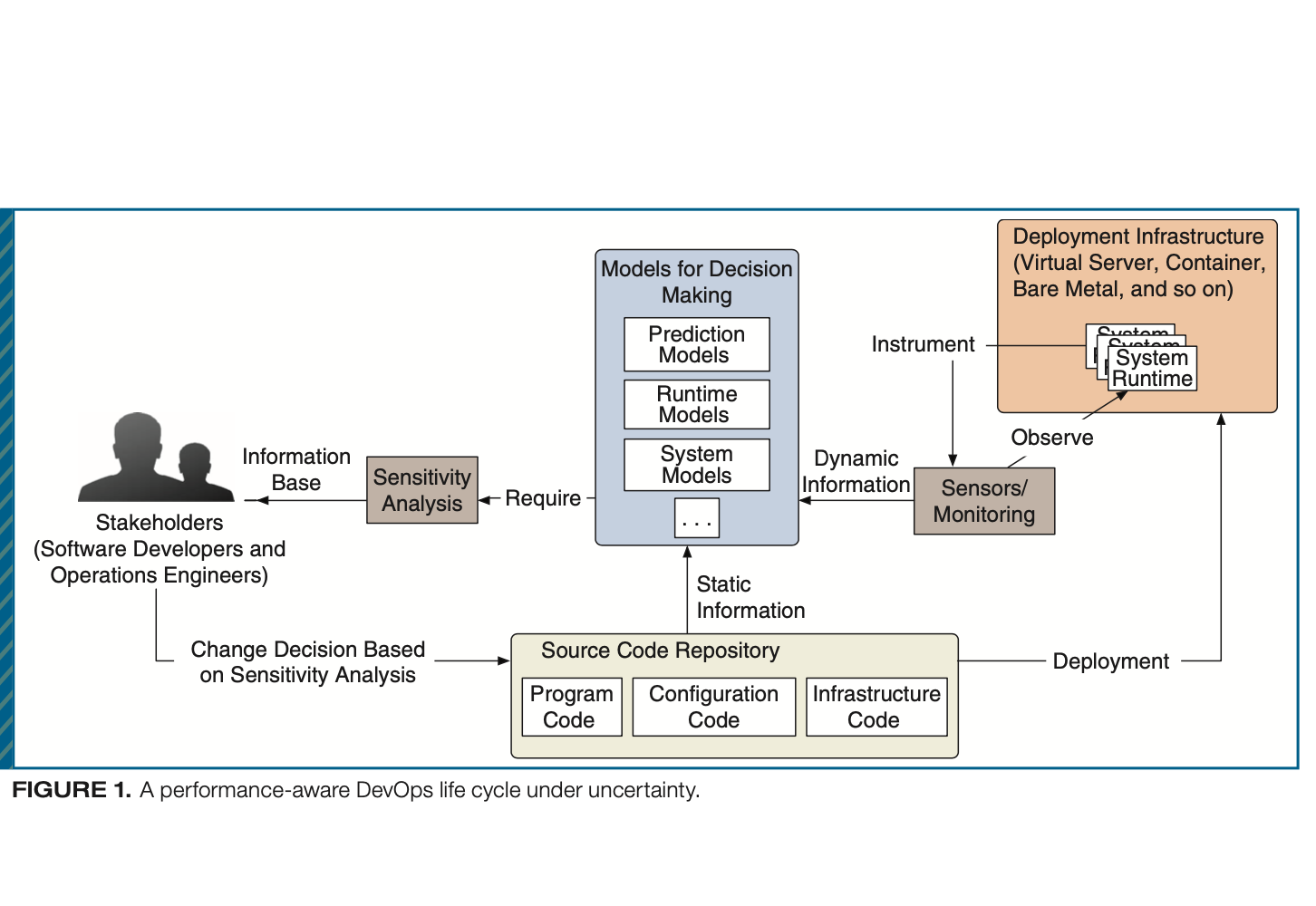
Catia Trubiani, Pooyan Jamshidi, Jurgen Cito, Weiyi Shang, Zhen Ming Jiang, Markus Borg
IEEE Software
Abstract
DevOps is a novel trend that aims to bridge the gap between software development and operation teams. This article presents an experience report that better identifies performance uncertainties through a case study and provides a step-by-step guide to practitioners for controlling system uncertainties.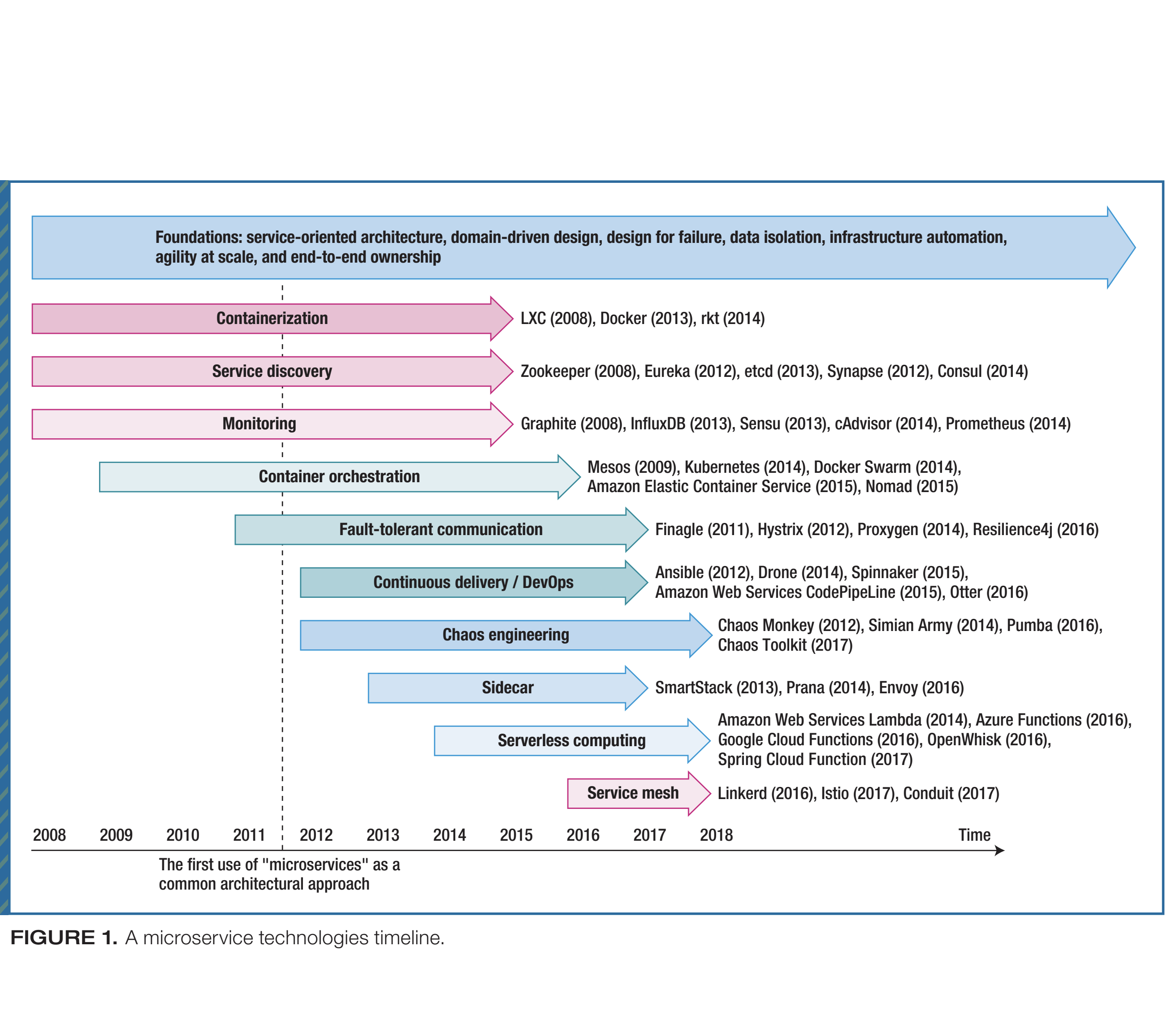
Pooyan Jamshidi, Claus Pahl, Nabor C. Mendonca, James Lewis, Stefan Tilkov
IEEE Software
Abstract
Microservices are an architectural approach emerging out of service-oriented architecture, emphasizing self-management and lightweightness as the means to improve software agility, scalability, and autonomy. This article examines microservice evolution from the technological and architectural perspectives and discusses key challenges facing future microservice developments.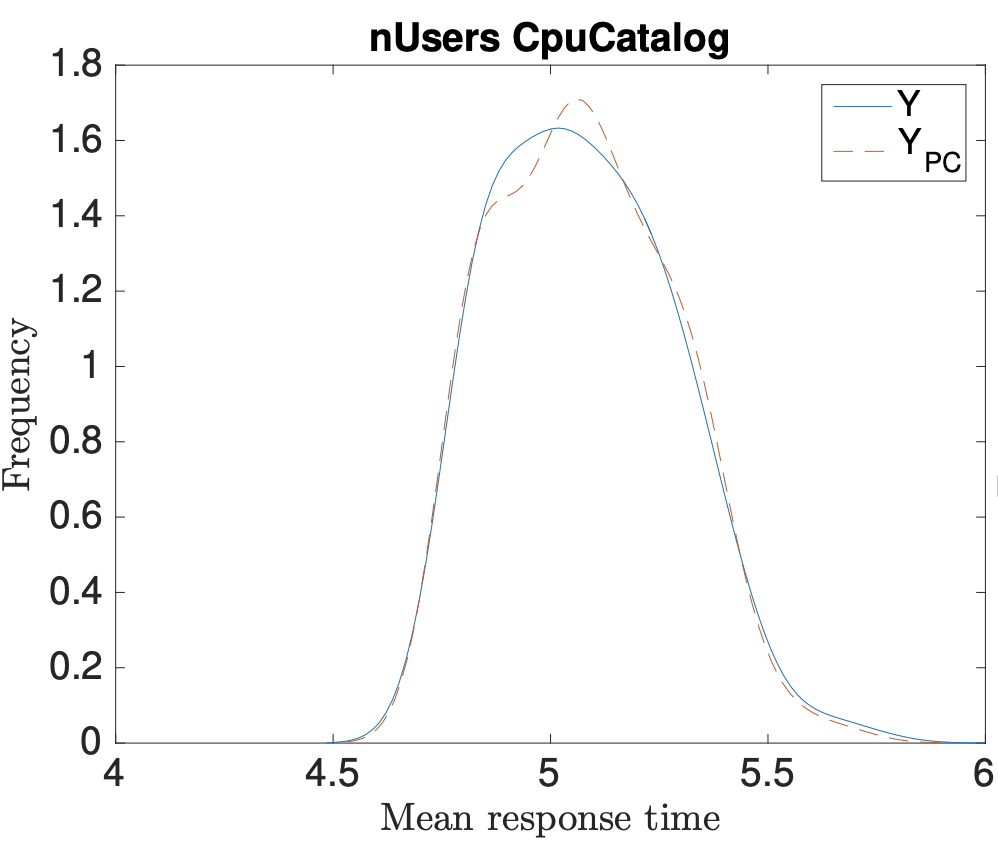
Aldeida Aleti, Catia Trubiani, Andre van Hoorn, Pooyan Jamshidi
Journal of Systems and Software (JSS)
Abstract
Software engineers often have to estimate the performance of a software system before having full knowledge of the system parameters, such as workload and operational profile. These uncertain parameters inevitably affect the accuracy of quality evaluations, and the ability to judge if the system can continue to fulfil performance requirements if parameter results are different from expected. Previous work has addressed this problem by modelling the potential values of uncertain parameters as probability distribution functions, and estimating the robustness of the system using Monte Carlo-based methods. These approaches require a large number of samples, which results in high computational cost and long waiting times. To address the computational inefficiency of existing approaches, we employ Polynomial Chaos Expansion (PCE) as a rigorous method for uncertainty propagation and further extend its use to robust performance estimation. The aim is to assess if the software system is robust, i.e., it can withstand possible changes in parameter values, and continue to meet performance requirements. PCE is a very efficient technique, and requires significantly less computations to accurately estimate the distribution of performance indices. Through three very different case studies from different phases of software development and heterogeneous application domains, we show that PCE can accurately estimate the robustness of various performance indices, and saves up to 225 hours of performance evaluation time when compared to Monte Carlo Simulation.
Armin Balalaie, A. Heydarnoori, Pooyan Jamshidi, Damian Tamburri, Theo Lynn
Software Practice and Experience (SPE)
Abstract
Microservices architectures are becoming the defacto standard for building continuously deployed systems. At the same time, there is a substantial growth in the demand for migrating on‐premise legacy applications to the cloud. In this context, organizations tend to migrate their traditional architectures into cloud‐native architectures using microservices. This article reports a set of migration and rearchitecting design patterns that we have empirically identified and collected from industrial‐scale software migration projects. These migration patterns can help information technology organizations plan their migration projects toward microservices more efficiently and effectively. In addition, the proposed patterns facilitate the definition of migration plans by pattern composition. Qualitative empirical research is used to evaluate the validity of the proposed patterns. Our findings suggest that the proposed patterns are evident in other architectural refactoring and migration projects and strong candidates for effective patterns in system migrations.
Claus Pahl, Pooyan Jamshidi, Olaf Zimmermann
ACM Transactions on Internet Technology (TOIT)
Abstract
A cloud is a distributed Internet-based software system providing resources as tiered services. Through service-orientation and virtualization for resource provisioning, cloud applications can be deployed and managed dynamically. We discuss the building blocks of an architectural style for cloud-based software systems. We capture style-defining architectural principles and patterns for control-theoretic, model-based architectures for cloud software. While service orientation is agreed on in the form of service-oriented architecture and microservices, challenges resulting from multi-tiered, distributed and heterogeneous cloud architectures cause uncertainty that has not been sufficiently addressed. We define principles and patterns needed for effective development and operation of adaptive cloud-native systems.2017
Claus Pahl, Antonio Brogi, Jacopo Soldani, Pooyan Jamshidi
IEEE Transactions on Cloud Computing (TCC)
Abstract
Containers as a lightweight technology to virtualise applications have recently been successful, particularly to manage applications in the cloud. Often, the management of clusters of containers becomes essential and the orchestration of the construction and deployment becomes a central problem. This emerging topic has been taken up by researchers, but there is currently no secondary study to consolidate this research. We aim to identify, taxonomically classify and systematically compare the existing research body on containers and their orchestration and specifically the application of this technology in the cloud. We have conducted a systematic mapping study of 46 selected studies. We classified and compared the selected studies based on a characterisation framework. This results in a discussion of agreed and emerging concerns in the container orchestration space, positioning it within the cloud context, but also moving it closer to current concerns in cloud platforms, microservices and continuous development.
Pooyan Jamshidi, Norbert Siegmund, Miguel Velez, Christian Kaestner, Akshay Patel, Yuvraj Agarwal
Automated Software Engineering (ASE 2017)
Abstract
Modern software systems provide many configuration options which significantly influence their non-functional properties. To understand and predict the effect of configuration options, several sampling and learning strategies have been proposed, albeit often with significant cost to cover the highly dimensional configuration space. Recently, transfer learning has been applied to reduce the effort of constructing performance models by transferring knowledge about performance behavior across environments. While this line of research is promising to learn more accurate models at a lower cost, it is unclear why and when transfer learning works for performance modeling. To shed light on when it is beneficial to apply transfer learning, we conducted an empirical study on four popular software systems, varying software configurations and environmental conditions, such as hardware, workload, and software versions, to identify the key knowledge pieces that can be exploited for transfer learning. Our results show that in small environmental changes (e.g., homogeneous workload change), by applying a linear transformation to the performance model, we can understand the performance behavior of the target environment, while for severe environmental changes (e.g., drastic workload change) we can transfer only knowledge that makes sampling more efficient, e.g., by reducing the dimensionality of the configuration space.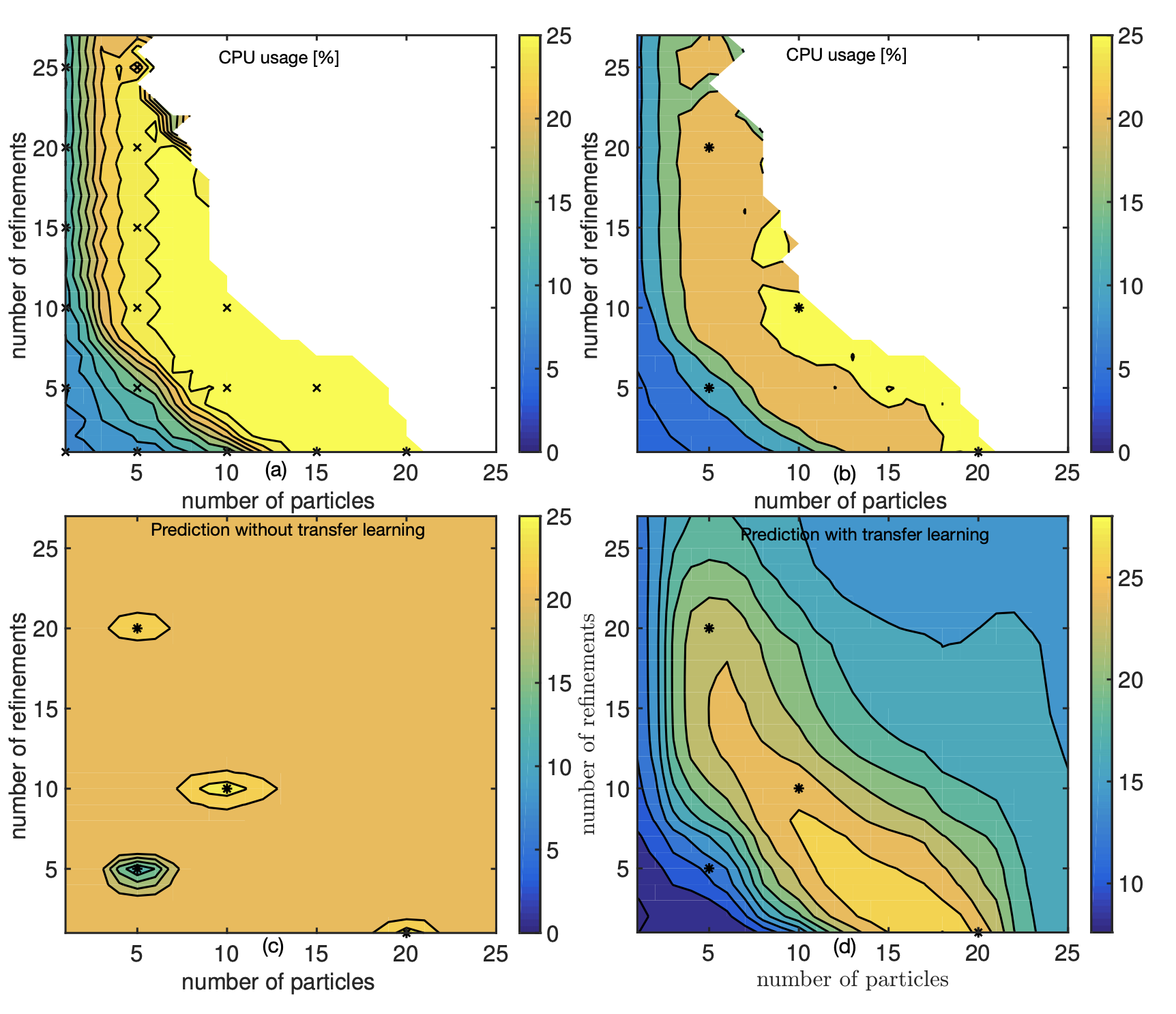
Pooyan Jamshidi, Miguel Velez, Christian Kaestner, Norbert Siegmund, Prasad Kawthekar
Software Engineering for Adaptive and Self-Managing Systems (SEAMS 2017)
Abstract
Modern software systems are built to be used in dynamic environments using configuration capabilities to adapt to changes and external uncertainties. In a self-adaptation context, we are often interested in reasoning about the performance of the systems under different configurations. Usually, we learn a black-box model based on real measurements to predict the performance of the system given a specific configuration. However, as modern systems become more complex, there are many configuration parameters that may interact and we end up learning an exponentially large configuration space. Naturally, this does not scale when relying on real measurements in the actual changing environment. We propose a different solution: Instead of taking the measurements from the real system, we learn the model using samples from other sources, such as simulators that approximate performance of the real system at low cost. We define a cost model that transform the traditional view of model learning into a multi-objective problem that not only takes into account model accuracy but also measurements effort as well. We evaluate our cost-aware transfer learning solution using real-world configurable software including (i) a robotic system, (ii) 3 different stream processing applications, and (iii) a NoSQL database system. The experimental results demonstrate that our approach can achieve (a) a high prediction accuracy, as well as (b) a high model reliability.
Claus Pahl, Pooyan Jamshidi, Danny Weyns
Journal of Software: Evolution and Process (JSEP)
Abstract
Cloud systems provide elastic execution environments of resources that link application and infrastructure/platform components, which are both exposed to uncertainties and change. Change appears in 2 forms: the evolution of architectural components under changing requirements and the adaptation of the infrastructure running applications. Cloud architecture continuity refers to the ability of a cloud system to change its architecture and maintain the validity of the goals that determine the architecture. Goal validity implies the satisfaction of goals in adapting or evolving systems. Architecture continuity aids technical sustainability, that is, the longevity of information, systems, and infrastructure and their adequate evolution with changing conditions. In a cloud setting that requires both steady alignment with technological evolution and availability, architecture continuity directly impacts economic sustainability. We investigate change models and change rules for managing change to support cloud architecture continuity. These models and rules define transformations of architectures to maintain system goals: Evolution is about unanticipated change of structural aspects of architectures, and adaptation is about anticipated change of architecture configurations. Both are driven by quality and cost, and both represent multidimensional decision problems under uncertainty. We have applied the models and rules for adaptation and evolution in research and industry consultancy projects.
Pooyan Jamshidi, Claus Pahl, Nabor C. Mendonca
Software: Practice and Experience (JSEP)
Abstract
Many organizations migrate on‐premise software applications to the cloud. However, current coarse‐grained cloud migration solutions have made such migrations a non transparent task, an endeavor based on trial‐and‐error. This paper presents Variability‐based, Pattern‐driven Architecture Migration (V‐PAM), a migration method based on (i) a catalogue of fine‐grained service‐based cloud architecture migration patterns that target multi‐cloud, (ii) a situational migration process framework to guide pattern selection and composition, and (iii) a variability model to structure system migration into a coherent framework. The proposed migration patterns are based on empirical evidence from several migration projects, best practice for cloud architectures and a systematic literature review of existing research. Variability‐based, Pattern‐driven Architecture Migration allows an organization to (i) select appropriate migration patterns, (ii) compose them to define a migration plan, and (iii) extend them based on the identification of new patterns in new contexts. The patterns are at the core of our solution, embedded into a process model, with their selection governed by a variability model.
A. Filieri, M. Maggio, K. Angelopoulos, N. D'Ippolito, I. Gerostathopoulos, A. Hempel, H. Hoffmann, P. Jamshidi, E. Kalyvianaki, C. Klein, F. Krikava, S. Misailovic, A. Papadopoulos, S. Ray, A. M. Sharifloo, S. Shevtsov, M. Ujma, T. Vogel
ACM Transactions on Autonomous and Adaptive Systems (TAAS)
Abstract
The pervasiveness and growing complexity of software systems are challenging software engineering to design systems that can adapt their behavior to withstand unpredictable, uncertain, and continuously changing execution environments. Control theoretical adaptation mechanisms have received growing interest from the software engineering community in the last few years for their mathematical grounding, allowing formal guarantees on the behavior of the controlled systems. However, most of these mechanisms are tailored to specific applications and can hardly be generalized into broadly applicable software design and development processes. This article discusses a reference control design process, from goal identification to the verification and validation of the controlled system. A taxonomy of the main control strategies is introduced, analyzing their applicability to software adaptation for both functional and nonfunctional goals. A brief extract on how to deal with uncertainty complements the discussion. Finally, the article highlights a set of open challenges, both for the software engineering and the control theory research communities.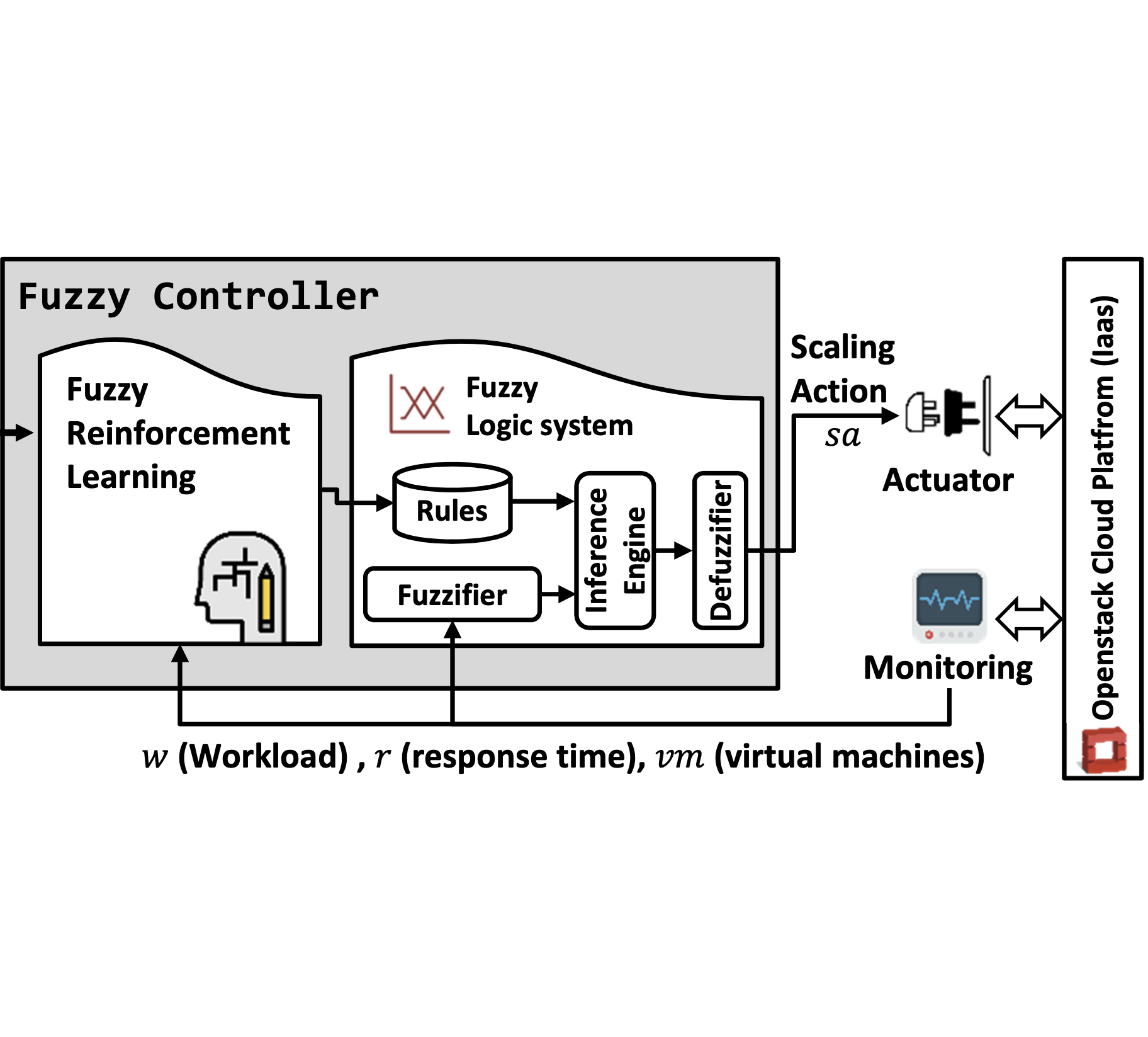
Hamid Arabnejad, Claus Pahl, Pooyan Jamshidi, Giovani Estrada
Cluster, Cloud and Internet Computing (CCGRID 2017)
Abstract
A goal of cloud service management is to design self-adaptable auto-scaler to react to workload fluctuations and changing the resources assigned. The key problem is how and when to add/remove resources in order to meet agreed service-level agreements. Reducing application cost and guaranteeing service-level agreements (SLAs) are two critical factors of dynamic controller design. In this paper, we compare two dynamic learning strategies based on a fuzzy logic system, which learns and modifies fuzzy scaling rules at runtime. A self-adaptive fuzzy logic controller is combined with two reinforcement learning (RL) approaches: (i) Fuzzy SARSA learning (FSL) and (ii) Fuzzy Q-learning (FQL). As an off-policy approach, Q-learning learns independent of the policy currently followed, whereas SARSA as an on-policy always incorporates the actual agent's behavior and leads to faster learning. Both approaches are implemented and compared in their advantages and disadvantages, here in the OpenStack cloud platform. We demonstrate that both auto-scaling approaches can handle various load traffic situations, sudden and periodic, and delivering resources on demand while reducing operating costs and preventing SLA violations. The experimental results demonstrate that FSL and FQL have acceptable performance in terms of adjusted number of virtual machine targeted to optimize SLA compliance and response time.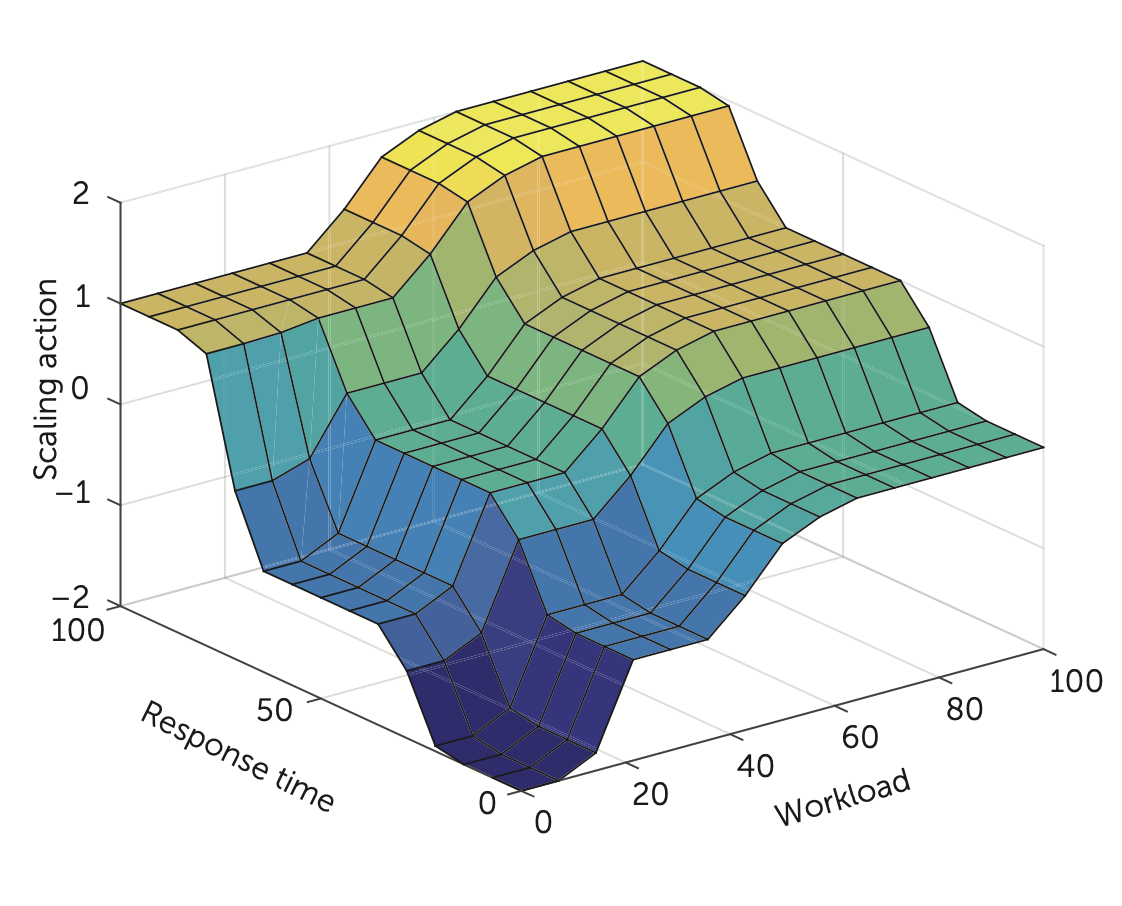
Pooyan Jamshidi, Claus Pahl, Nabor C. Mendonca
IEEE Cloud Computing
Abstract
Elasticity allows a cloud system to maintain an optimal user experience by automatically acquiring and releasing resources. Autoscaling-adding or removing resources automatically on the fly-involves specifying threshold-based rules to implement elasticity policies. However, the elasticity rules must be specified through quantitative values, which requires cloud resource management knowledge and expertise. Furthermore, existing approaches don't explicitly deal with uncertainty in cloud-based software, where noise and unexpected events are common. The authors propose a control-theoretic approach that manages the behavior of a cloud environment as a dynamic system. They integrate a fuzzy cloud controller with an online learning mechanism, putting forward a framework that takes the human out of the dynamic adaptation loop and can cope with various sources of uncertainty in the cloud.2016
Pooyan Jamshidi, Giuliano Casale
Modeling, Analysis, and Simulation of Computer Systems (MASCOTS 2016)
Abstract
Finding optimal configurations for Stream Processing Systems (SPS) is a challenging problem due to the large number of parameters that can influence their performance and the lack of analytical models to anticipate the effect of a change. To tackle this issue, we consider tuning methods where an experimenter is given a limited budget of experiments and needs to carefully allocate this budget to find optimal configurations. We propose in this setting Bayesian Optimization for Configuration Optimization (BO4CO), an auto-tuning algorithm that leverages Gaussian Processes (GPs) to iteratively capture posterior distributions of the configuration spaces and sequentially drive the experimentation. Validation based on Apache Storm demonstrates that our approach locates optimal configurations within a limited experimental budget, with an improvement of SPS performance typically of at least an order of magnitude compared to existing configuration algorithms.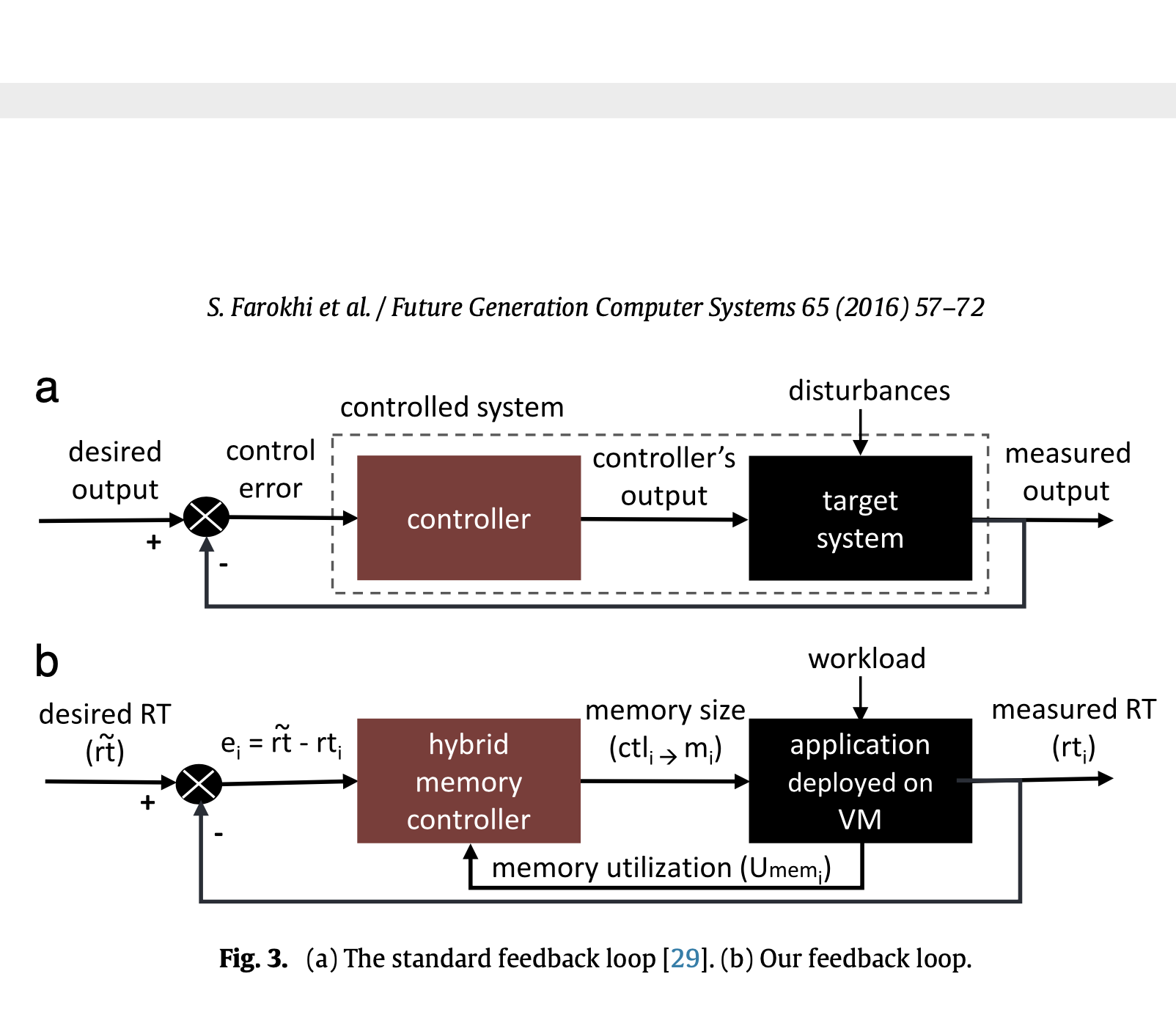
Soodeh Farokhi, Pooyan Jamshidi, Ewnetu Bayuh Lakew, Ivona Brandic, Erik Elmroth
Future Generation Computer Systems (FGCS)
Abstract
Web-facing applications are expected to provide certain performance guarantees despite dynamic and continuous workload changes. As a result, application owners are using cloud computing as it offers the ability to dynamically provision computing resources (e.g., memory, CPU) in response to changes in workload demands to meet performance targets and eliminates upfront costs. Horizontal, vertical, and the combination of the two are the possible dimensions that cloud application can be scaled in terms of the allocated resources. In vertical elasticity as the focus of this work, the size of virtual machines (VMs) can be adjusted in terms of allocated computing resources according to the runtime workload. A commonly used vertical resource elasticity approach is realized by deciding based on resource utilization, named capacity-based. While a new trend is to use the application performance as a decision making criterion, and such an approach is named performance-based. This paper discusses these two approaches and proposes a novel hybrid elasticity approach that takes into account both the application performance and the resource utilization to leverage the benefits of both approaches. The proposed approach is used in realizing vertical elasticity of memory (named as vertical memory elasticity), where the allocated memory of the VM is auto-scaled at runtime. To this aim, we use control theory to synthesize a feedback controller that meets the application performance constraints by auto-scaling the allocated memory, i.e., applying vertical memory elasticity. Different from the existing vertical resource elasticity approaches, the novelty of our work lies in utilizing both the memory utilization and application response time as decision making criteria. To verify the resource efficiency and the ability of the controller in handling unexpected workloads, we have implemented the controller on top of the Xen hypervisor and performed a series of experiments using the RUBBoS interactive benchmark application, under synthetic and real workloads including Wikipedia and FIFA. The results reveal that the hybrid controller meets the application performance target with better performance stability (i.e., lower standard deviation of response time), while achieving a high memory utilization (close to 83%), and allocating less memory compared to all other baseline controllers.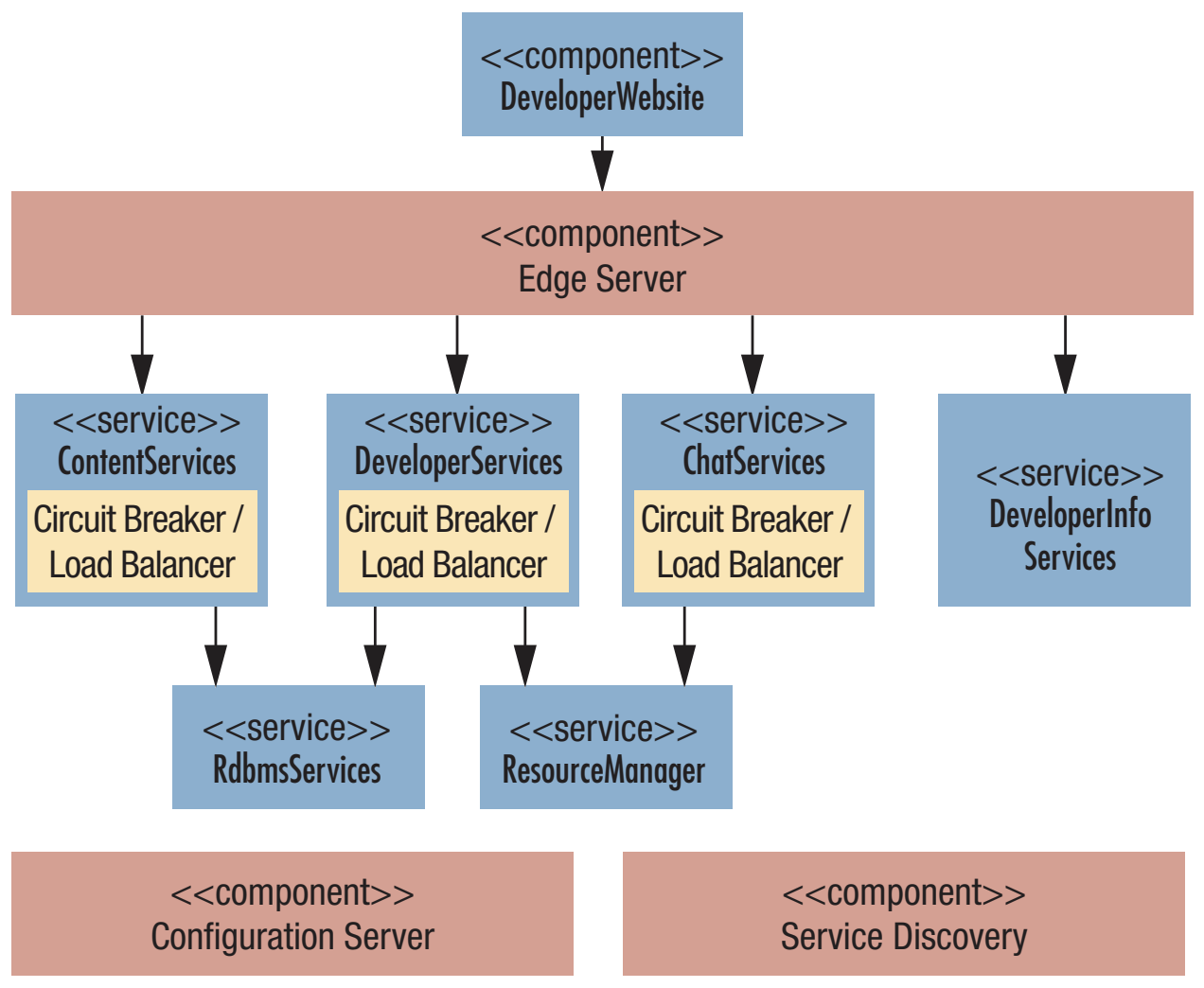
Armin Balalaie, Abbas Heydarnoori, Pooyan Jamshidi
IEEE Software
Abstract
This article reports on experiences and lessons learned during incremental migration and architectural refactoring of a commercial mobile back end as a service to microservices architecture. It explains how the researchers adopted DevOps and how this facilitated a smooth migration.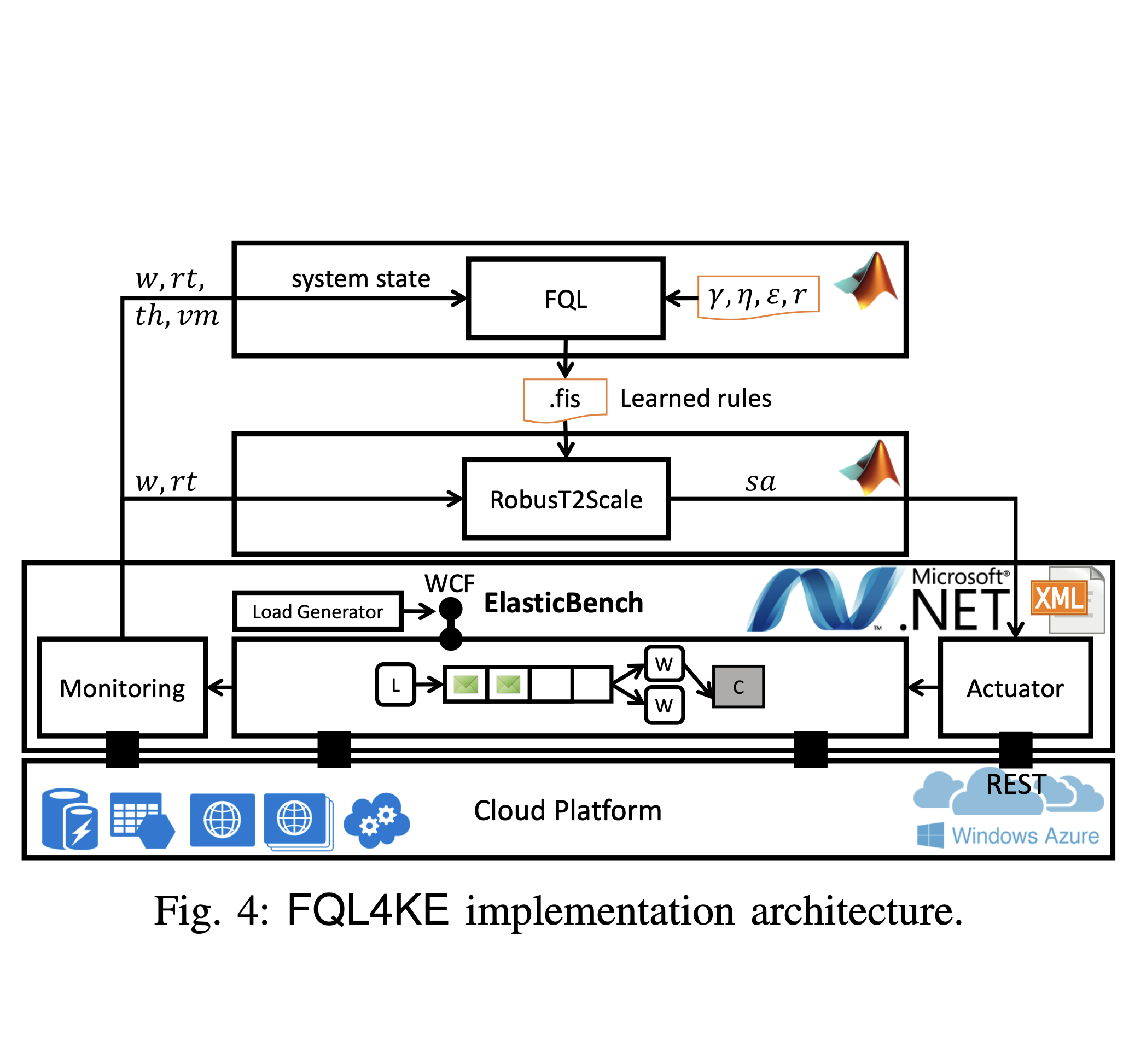
Pooyan Jamshidi, Amir Sharifloo, Claus Pahl, Hamid Arabnejad, Andreas Metzger, Giovani Estrada
Quality of Software Architectures (QoSA 2016)
Abstract
Cloud controllers support the operation and quality management of dynamic cloud architectures by automatically scaling the compute resources to meet performance guarantees and minimize resource costs. Existing cloud controllers often resort to scaling strategies that are codified as a set of architecture adaptation rules. However, for a cloud provider, deployed application architectures are black-boxes, making it difficult at design time to define optimal or pre-emptive adaptation rules. Thus, the burden of taking adaptation decisions often is delegated to the cloud application. We propose the dynamic learning of adaptation rules for deployed application architectures in the cloud. We introduce FQL4KE, a self-learning fuzzy controller that learns and modifies fuzzy rules at runtime. The benefit is that we do not have to rely solely on precise design-time knowledge, which may be difficult to acquire. FQL4KE empowers users to configure cloud controllers by simply adjusting weights representing priorities for architecture quality instead of defining complex rules. FQL4KE has been experimentally validated using the cloud application framework ElasticBench in Azure and OpenStack. The experimental results demonstrate that FQL4KE outperforms both a fuzzy controller without learning and the native Azure auto-scaling.
Frank Fowley, Claus Pahl, Pooyan Jamshidi, Daren Fang, Xiaodong Liu
IEEE Transactions on Cloud Computing (TCC)
Abstract
Cloud service brokerage and related management and marketplace concepts have been identified as key concerns for future cloud technology development and research. Cloud service management is an important building block of cloud architectures that can be extended to act as a broker service layer between consumers and providers, and even to form marketplace services. We present a three-pronged classification and comparison framework for broker platforms and applications. A range of specific broker development concerns like architecture, programming and quality are investigated. Based on this framework, selected management, brokerage and marketplace solutions will be compared, not only to demonstrate the utility of the framework, but also to identify challenges and wider research objectives based on an identification of cloud broker architecture concerns and technical requirements for service brokerage solutions. We also discuss emerging cloud architecture concerns such as commoditisation and federation of integrated, vertical cloud stacks.2015
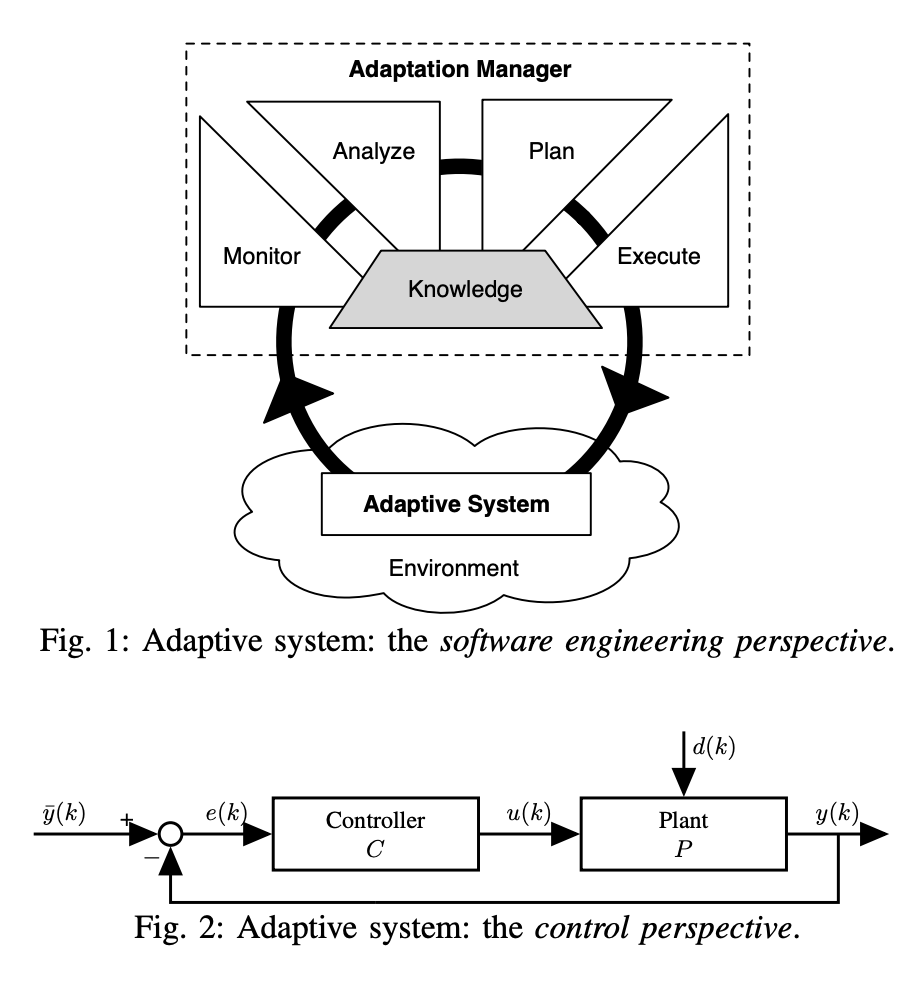
A. Filieri, M. Maggio, K. Angelopoulos, N. D'Ippolito, I. Gerostathopoulos, A. Hempel, H. Hoffmann, P. Jamshidi, E. Kalyvianaki, C. Klein, F. Krikava, S. Misailovic, A. Papadopoulos, S. Ray, A. M. Sharifloo, S. Shevtsov, M. Ujma, T. Vogel
Software Engineering for Adaptive and Self-Managing Systems (SEAMS 2015)
Abstract
The software engineering community has proposed numerous approaches for making software self-adaptive. These approaches take inspiration from machine learning and control theory, constructing software that monitors and modifies its own behavior to meet goals. Control theory, in particular, has received considerable attention as it represents a general methodology for creating adaptive systems. Control-theoretical software implementations, however, tend to be ad hoc. While such solutions often work in practice, it is difficult to understand and reason about the desired properties and behavior of the resulting adaptive software and its controller. This paper discusses a control design process for software systems which enables automatic analysis and synthesis of a controller that is guaranteed to have the desired properties and behavior. The paper documents the process and illustrates its use in an example that walks through all necessary steps for self-adaptive controller synthesis.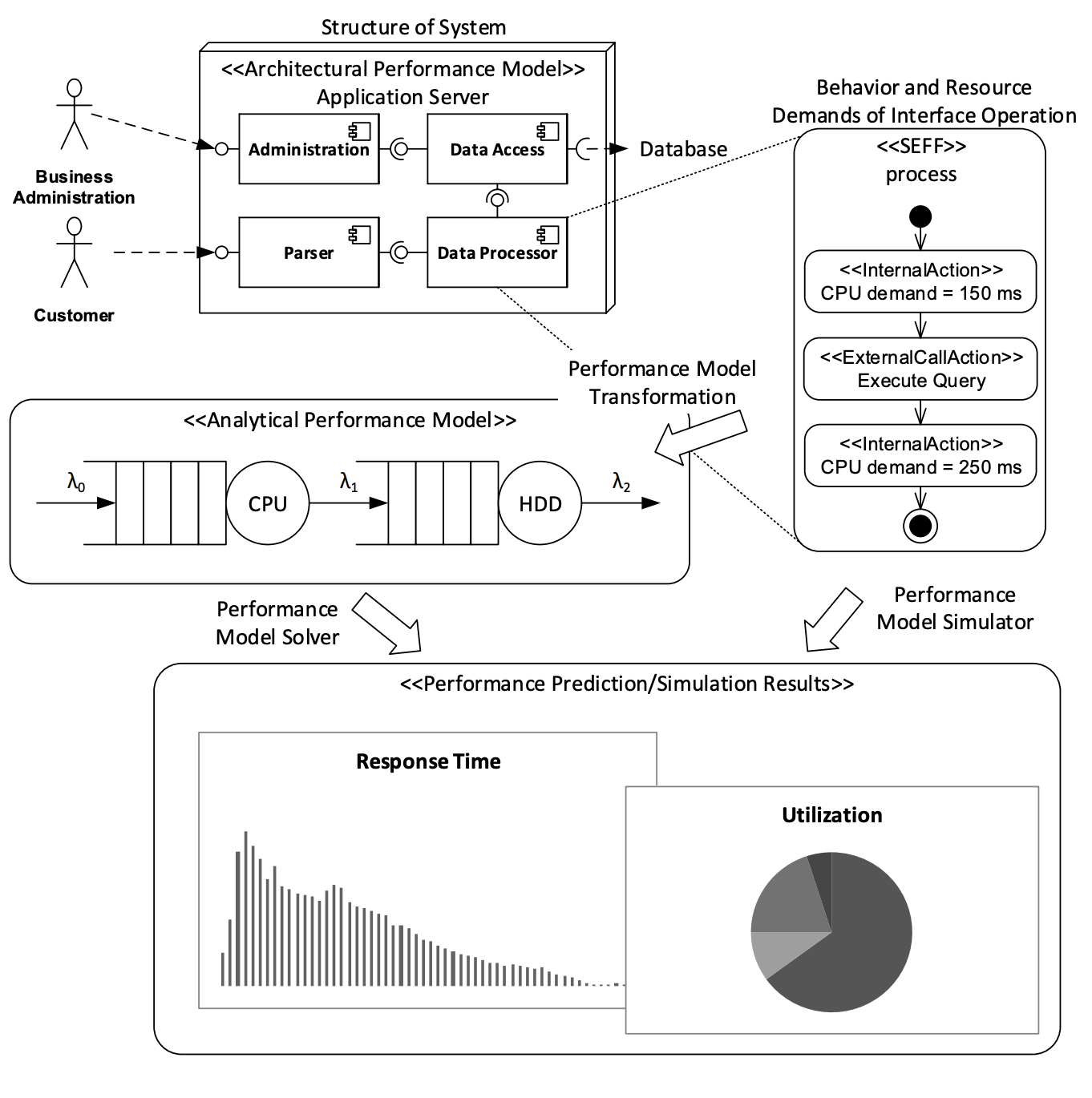
A. Brunnert, A. Hoorn, F. Willnecker, A. Danciu, W. Hasselbring, C. Heger, N. Herbst, P. Jamshidi, R. Jung, J. Kistowski, A. Koziolek, J. Kroß, S. Spinner, C. Vögele, J. Walter, A. Wert
Technical Report
Abstract
DevOps is a trend towards a tighter integration between development (Dev) and operations (Ops) teams. The need for such an integration is driven by the requirement to continuously adapt enterprise applications (EAs) to changes in the business environment. As of today, DevOps concepts have been primarily introduced to ensure a constant flow of features and bug fixes into new releases from a functional perspective. In order to integrate a non-functional perspective into these DevOps concepts this report focuses on tools, activities, and processes to ensure one of the most important quality attributes of a software system, namely performance. Performance describes system properties concerning its timeliness and use of resources. Common metrics are response time, throughput, and resource utilization. Performance goals for EAs are typically defined by setting upper and/or lower bounds for these metrics and specific business transactions. In order to ensure that such performance goals can be met, several activities are required during development and operation of these systems as well as during the transition from Dev to Ops. Activities during development are typically summarized by the term Software Performance Engineering (SPE), whereas activities during operations are called Application Performance Management (APM). SPE and APM were historically tackled independently from each other, but the newly emerging DevOps concepts require and enable a tighter integration between both activity streams. This report presents existing solutions to support this integration as well as open research challenges in this area.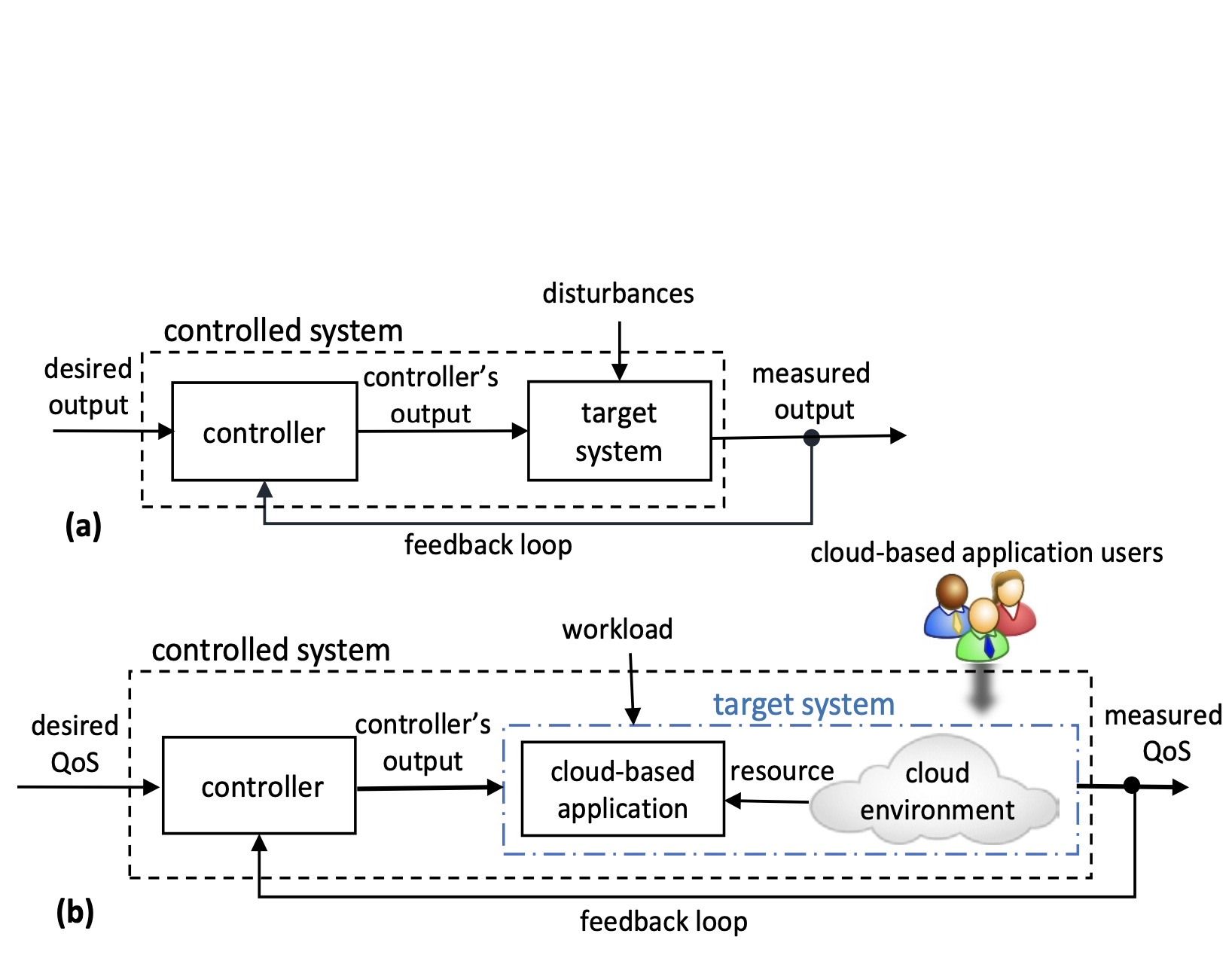
S. Farokhi, P. Jamshidi, I. Brandic, E. Elmroth
Feedback Computing (FC 2015)
Abstract
Software applications accessible over the web are typically subject to very dynamic workloads. Since cloud elasticity provides the ability to adjust the deployed environment on the fly, modern software systems tend to target cloud as a fertile deployment environment. However, relying only on native elasticity features of cloud service providers is not sufficient for modern applications. This is because current features rely on users’ knowledge for configuring the performance parameters of the elasticity mechanism and in general users cannot optimally determine such sensitive parameters. In order to overcome this user dependency, using approaches from autonomic computing is shown to be appropriate. Control theory proposes a systematic way to design feedback control loops to handle unpredictable changes at runtime for software applications. Although there are still substantial challenges to effectively utilize feedback control in self-adaptation of software systems, software engineering and control theory communities have made recent progress to consolidate their differences by identifying challenges that can be addressed cooperatively. This paper is in the same vein, but in a narrower domain given that cloud computing is a sub-domain of software engineering. It aims to highlight the challenges in the self-adaptation process of cloud-based applications in the perspective of control engineers.2014
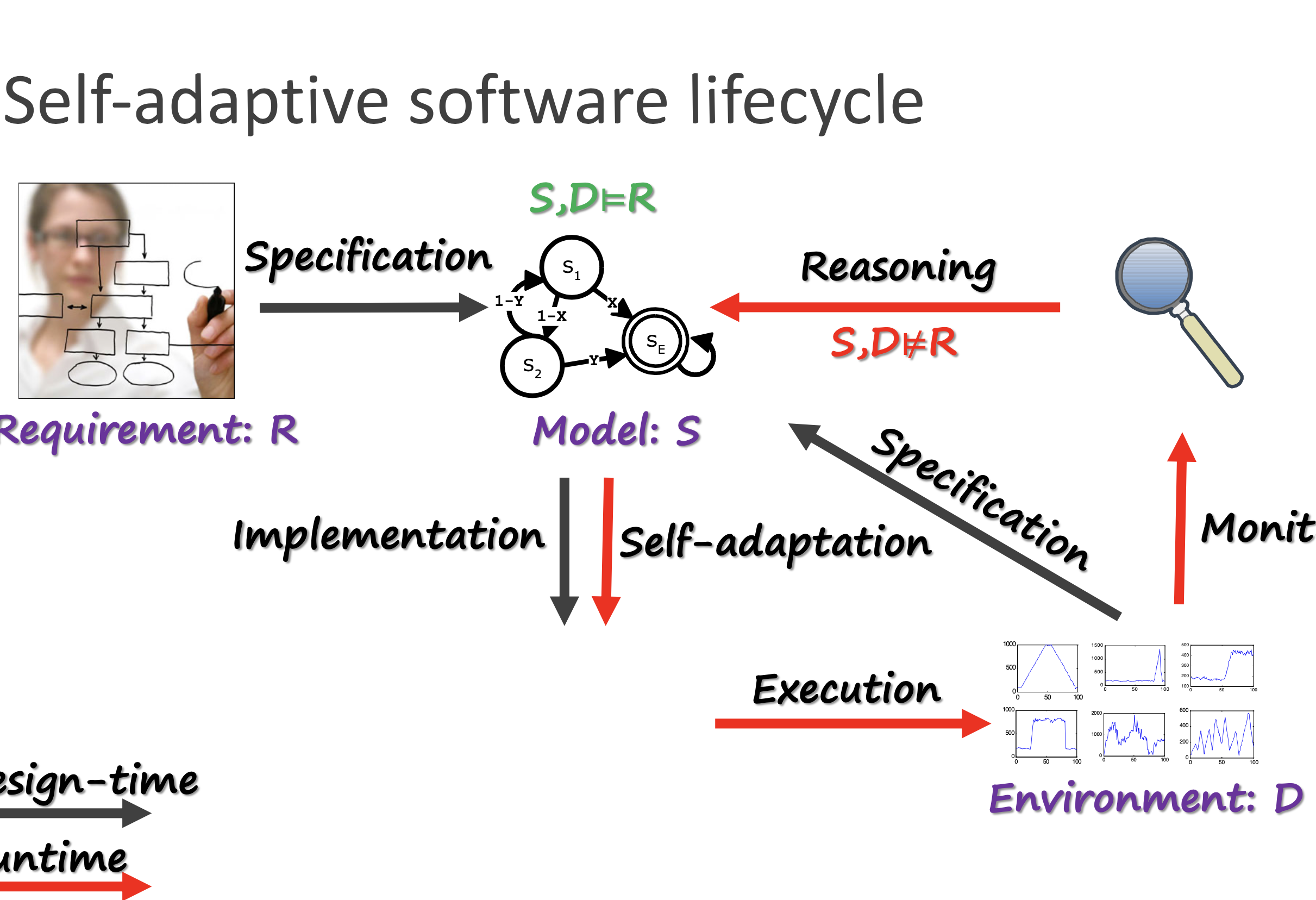
Pooyan Jamshidi
PhD Thesis
Abstract
We enable reliable and dependable self‐adaptations of component connectors in unreliable environments with imperfect monitoring facilities and conflicting user opinions about adaptation policies by developing a framework which comprises: (a) mechanisms for robust model evolution, (b) a method for adaptation reasoning, and (c) tool support that allows an end‐to‐end application of the developed techniques in real‐world domains.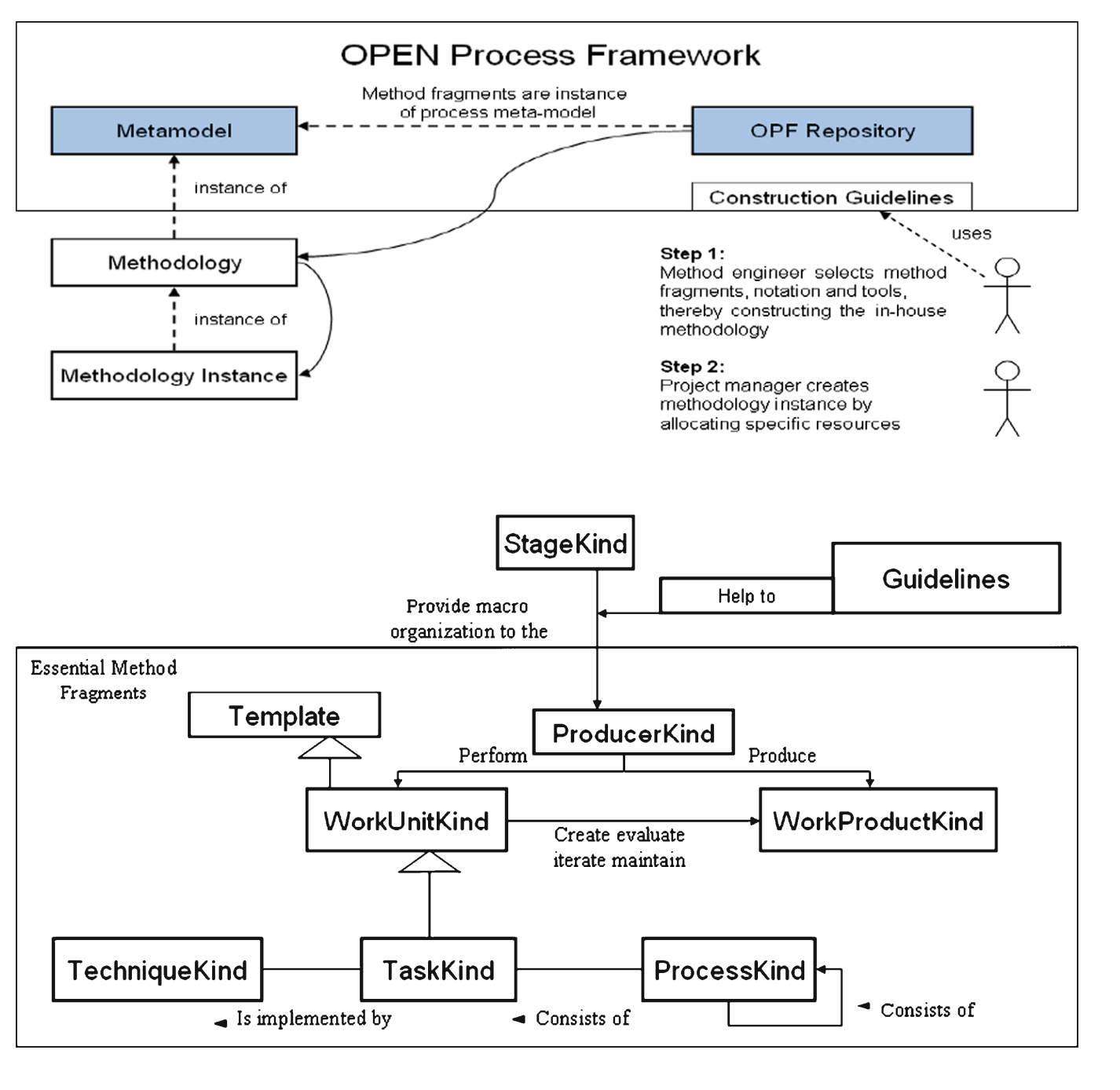
Mahdi Fahmideh Gholami, Mohsen Sharifi, Pooyan Jamshidi
Software and Systems Modeling (SoSym)
Abstract
Service orientation is a promising paradigm that enables the engineering of large-scale distributed software systems using rigorous software development processes. The existing problem is that every service-oriented software development project often requires a customized development process that provides specific service-oriented software engineering tasks in support of requirements unique to that project. To resolve this problem and allow situational method engineering, we have defined a set of method fragments in support of the engineering of the project-specific service-oriented software development processes. We have derived the proposed method fragments from the recurring features of 11 prominent service-oriented software development methodologies using a systematic mining approach. We have added these new fragments to the repository of OPEN Process Framework to make them available to software engineers as reusable fragments using this well-known method repository.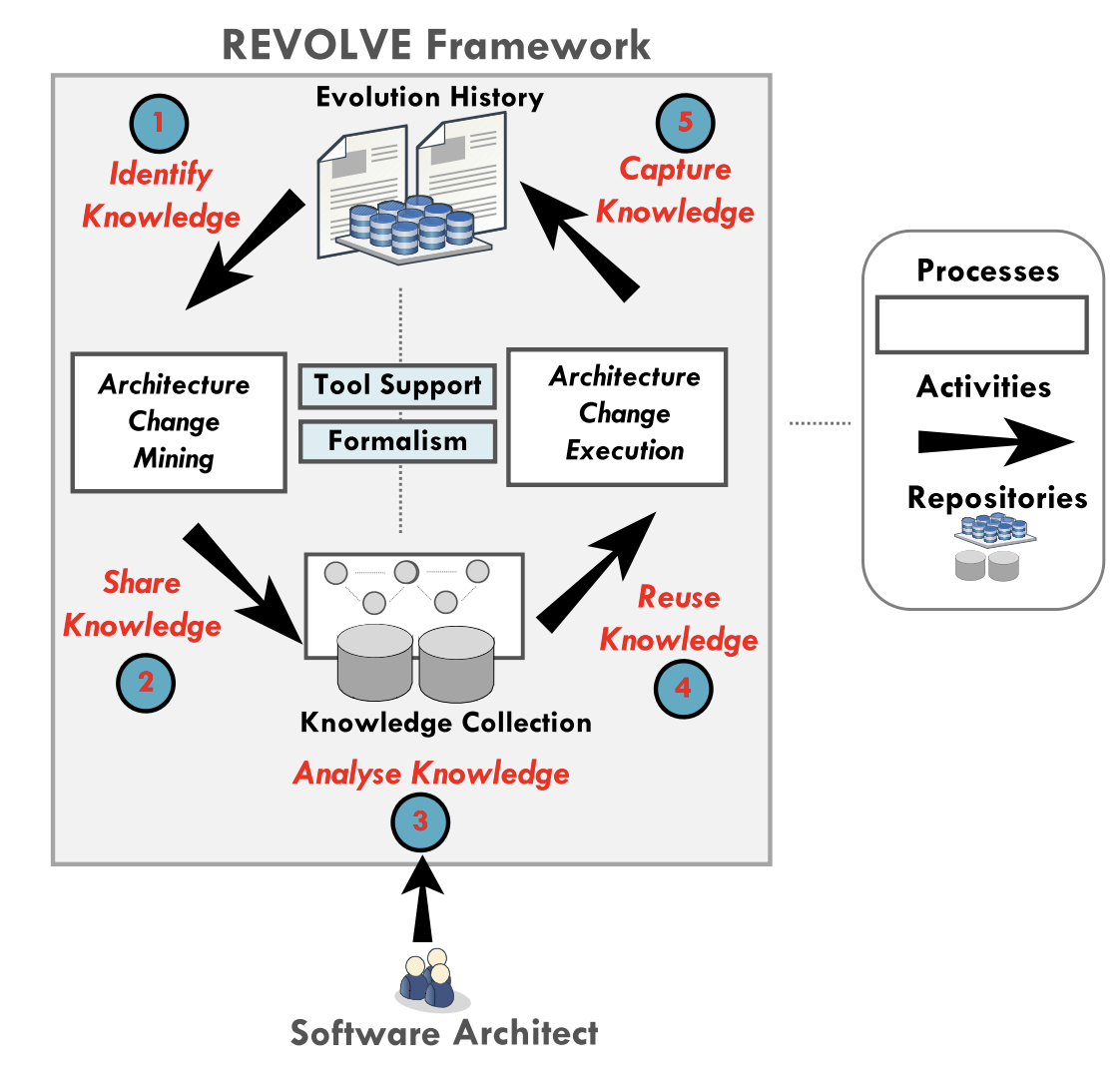
Aakash Ahmad, Pooyan Jamshidi, Claus Pahl
Wiley Journal of Software––Evolution and Process (JSEP)
Abstract
Architecture‐centric software evolution (ACSE) enables changes in system's structure and behaviour while maintaining a global view of the software to address evolution‐centric trade‐offs. The existing research and practices for ACSE primarily focus on design‐time evolution and runtime adaptations to accommodate changing requirements in existing architectures. We aim to identify, taxonomically classify and systematically compare the existing research focused on enabling or enhancing change reuse to support ACSE. We conducted a systematic literature review of 32 qualitatively selected studies and taxonomically classified these studies based on solutions that enable (i) empirical acquisition and (ii) systematic application of architecture evolution reuse knowledge (AERK) to guide ACSE. We identified six distinct research themes that support acquisition and application of AERK. We investigated (i) how evolution reuse knowledge is defined, classified and represented in the existing research to support ACSE and (ii) what are the existing methods, techniques and solutions to support empirical acquisition and systematic application of AERK. Change patterns (34% of selected studies) represent a predominant solution, followed by evolution styles (25%) and adaptation strategies and policies (22%) to enable application of reuse knowledge. Empirical methods for acquisition of reuse knowledge represent 19% including pattern discovery, configuration analysis, evolution and maintenance prediction techniques (approximately 6% each). A lack of focus on empirical acquisition of reuse knowledge suggests the need of solutions with architecture change mining as a complementary and integrated phase for architecture change execution.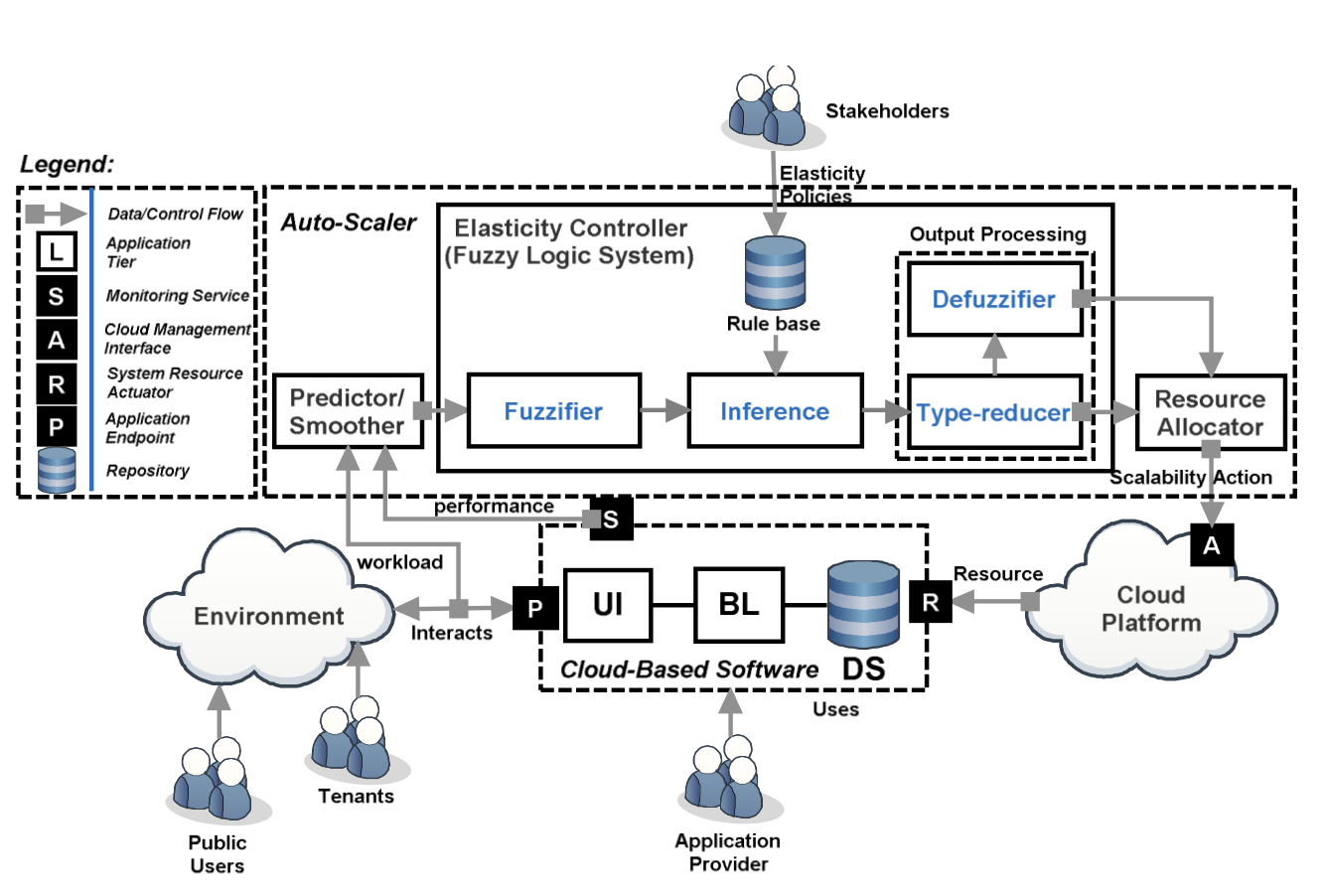
Pooyan Jamshidi, Aakash Ahmad, Claus Pahl
Software Engineering for Adaptive and Self-Managing Systems (SEAMS 2014)
Abstract
Cloud elasticity provides a software system with the ability to maintain optimal user experience by automatically acquiring and releasing resources, while paying only for what has been consumed. The mechanism for automatically adding or removing resources on the fly is referred to as auto-scaling. The state-of-the-practice with respect to auto-scaling involves specifying threshold-based rules to implement elasticity policies for cloud-based applications. However, there are several shortcomings regarding this approach. Firstly, the elasticity rules must be specified precisely by quantitative values, which requires deep knowledge and expertise. Furthermore, existing approaches do not explicitly deal with uncertainty in cloud-based software, where noise and unexpected events are common. This paper exploits fuzzy logic to enable qualitative specification of elasticity rules for cloud-based software. In addition, this paper discusses a control theoretical approach using type-2 fuzzy logic systems to reason about elasticity under uncertainties. We conduct several experiments to demonstrate that cloud-based software enhanced with such elasticity controller can robustly handle unexpected spikes in the workload and provide acceptable user experience. This translates into increased profit for the cloud application owner.2013
Pooyan Jamshidi, Aakash Ahmad, Claus Pahl
IEEE Transactions on Cloud Computing (TCC)
Abstract
Background--By leveraging cloud services, organizations can deploy their software systems over a pool of resources. However, organizations heavily depend on their business-critical systems, which have been developed over long periods. These legacy applications are usually deployed on-premise. In recent years, research in cloud migration has been carried out. However, there is no secondary study to consolidate this research. Objective--This paper aims to identify, taxonomically classify, and systematically compare existing research on cloud migration. Method--We conducted a systematic literature review (SLR) of 23 selected studies, published from 2010 to 2013. We classified and compared the selected studies based on a characterization framework that we also introduce in this paper. Results--The research synthesis results in a knowledge base of current solutions for legacy-to-cloud migration. This review also identifies research gaps and directions for future research. Conclusion--This review reveals that cloud migration research is still in early stages of maturity, but is advancing. It identifies the needs for a migration framework to help improving the maturity level and consequently trust into cloud migration. This review shows a lack of tool support to automate migration tasks. This study also identifies needs for architectural adaptation and self-adaptive cloud-enabled systems.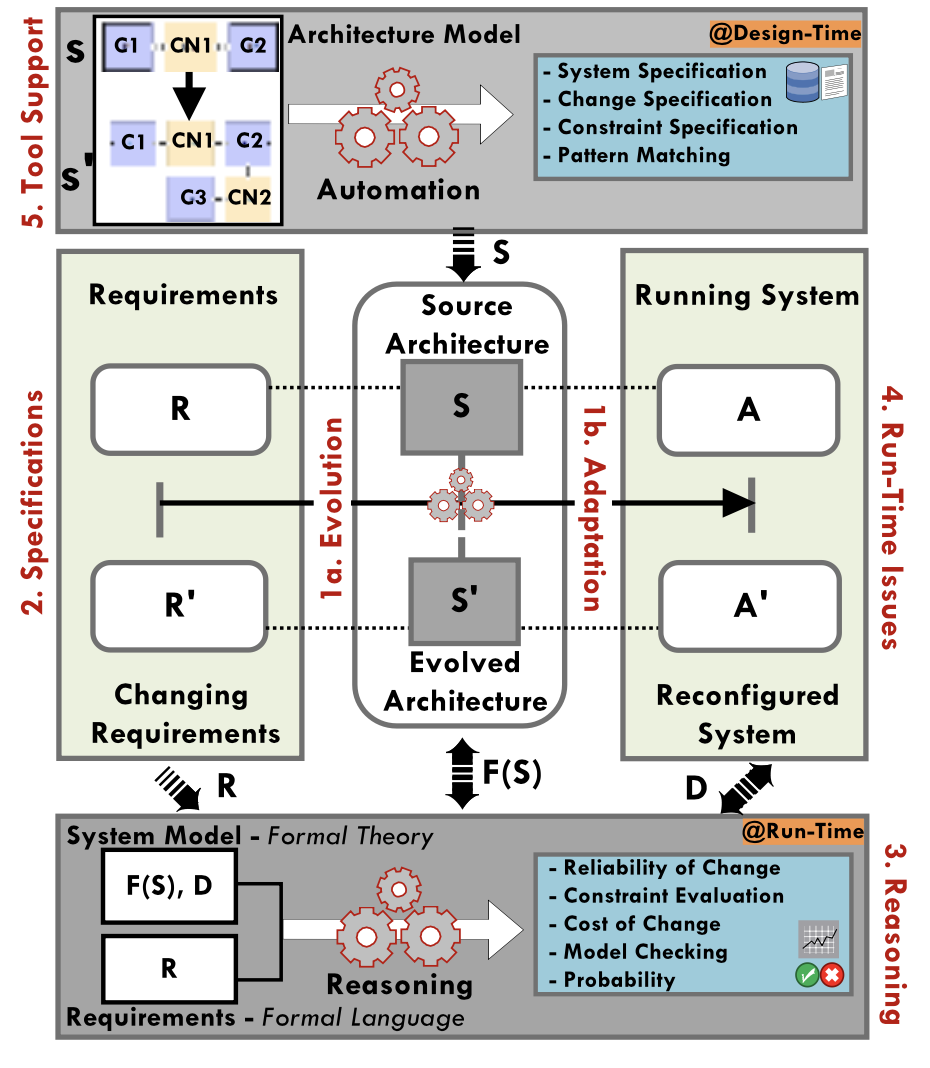
Pooyan Jamshidi, Mohammad Ghafari, Aakash Ahmad, Claus Pahl
Software Analysis, Evolution and Reengineering (SANER 2013)